AI/機械学習を実務に活かす:レコメンドコンペティション優勝解法徹底解説(1)
はじめに
DataRobotの詹金(センキン)と申します。シニアデータサイエンティストとしてお客様の分析プロジェクトを支援しています。前職では、ECサイトでレコメンドシステムの開発に携わり、これまでレコメンドシステムの精度を競う世界的なデータ分析コンペティションで複数回の入賞経験があります。
現在、多くのデジタルサービスプロバイダー、eコマース企業、ソーシャルメディアにおいて、レコメンドシステムが実装され、成功を収めている事例が多く見られます。これらの企業は、個々のユーザーにカスタマイズされたユーザー体験を提供することで、販売実績や広告収入の増加を目指しています。
具体的には、機械学習モデルを用いた強力なエンジンにより、購入や閲覧履歴などの大量の顧客データや行動パターンに基づいて顧客をセグメント化し、パーソナライズされた商品やコンテンツを提案しています。この手法により、ルールベースなどの従来手法と比べてレコメンドの精度は近年大幅に向上しています。皆様も、eコマースサイトなどを利用された時に、ご自身の興味に合った商品が推薦されていると感じているのではないでしょうか。
一方で、レコメンドシステムの詳しい仕組みについては、ご存じない方も多いかもしれません。そこで本稿と次稿の2編に渡り、読者の皆様が高精度なレコメンドシステムを構築するためのヒントとなる情報の提供を目的として、世界的なデータ分析コンペティションであるKaggleの「H&M Personalized Fashion Recommendations」[1]で筆者が優勝した時に用いた解法を基に、レコメンドシステムで使われる機械学習に関する暗黙知やノウハウを詳しく解説していきます(このコンペティションでのタスクは、ファッションブランドH&Mの購買データを題材に、顧客の行動履歴から、翌週に購入する商品をレコメンドすることでした)。
Two-Stage Recommendation Systemの概要
レコメンドシステムは、一般的に二つのステージから構成されており、「Two-Stage Recommendation System」などと呼ばれます。
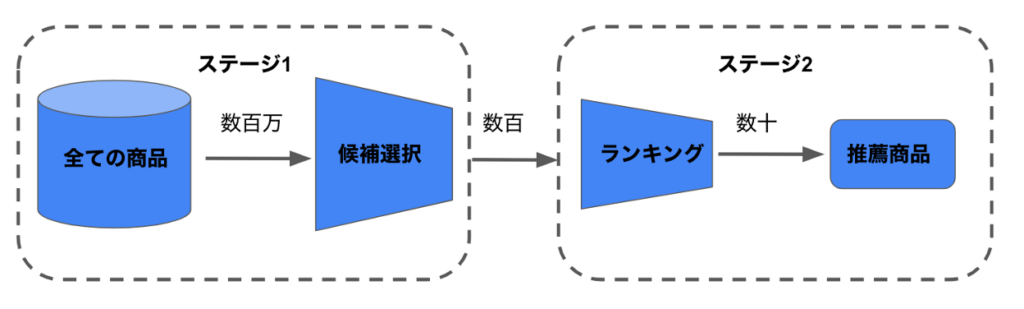
最初のステージ(ステージ1)は、推薦可能なすべての商品から数百の候補を選択する役割を担います。このステージの主な目的は、顧客が興味のない候補を効率的に除外することです。このステージでは何百万もの候補を扱う可能性があるため、計算効率が高くなければなりません。そのため、一般的には協調フィルタリングなどの統計的手法が利用されます。
次のステージ(ステージ2)はランキングです。最初のステージで選ばれた候補アイテムをさらに絞り込み、最終的な推薦を行います。このステージでは、候補商品と顧客の間のより詳細な関係や特徴を考慮します。顧客の個人的な嗜好や興味、コンテキスト情報なども考慮することで、よりパーソナライズされた推薦を行うことができます。このステージは精度改善を優先するため、大量の特徴量エンジニアリングや複雑なモデルが利用されます。
Two-Stage Recommendation Systemの一つの長所は、複雑なシステムをそのまま扱うのではなく、より単純な複数のシステムに分解できる点にあります。各ステージをモジュール化できるため、別々のチームが独立して各ステージを担当し、最適化に集中することができます。実際に筆者が参加した上記Kaggleコンペでは、チームメンバーがステージごとに作業に集中することで重複作業がなくなり、開発効率が大幅に向上しました。
候補生成ステージ(ステージ1)の徹底解説
データラベリング
機械学習プロジェクトでは、まずサンプル作成とラベル付けが必要です。レコメンドシステムの成功の第一歩は、高品質なサンプルを作成することです。
ここで、「人気商品」を候補とした推薦の例を紹介します。すべての顧客に対して人気Top5の商品を候補とし、顧客と商品のペアに対して、次の週に実際に購入した商品には正例、それ以外の商品には負例という二値ラベルを付与する方法です。
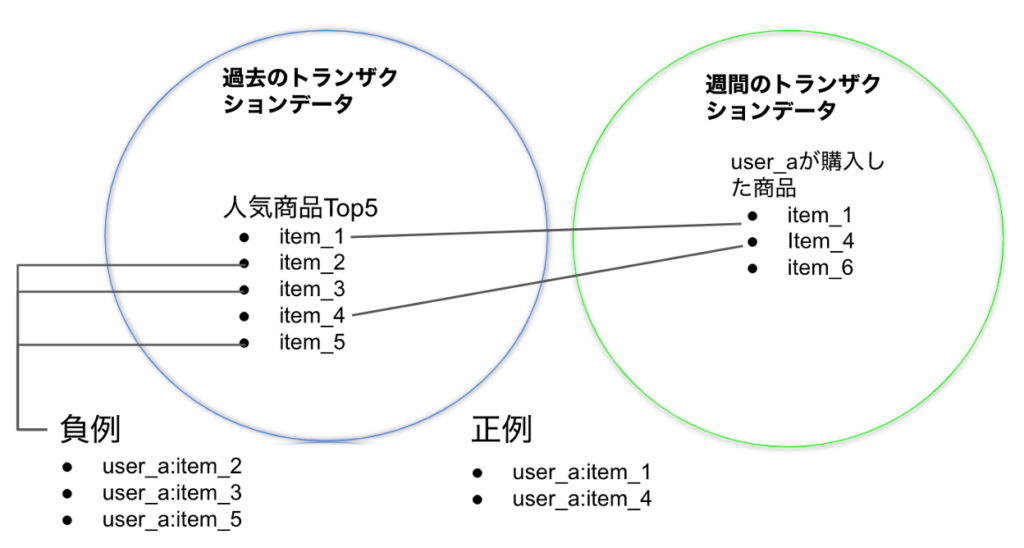
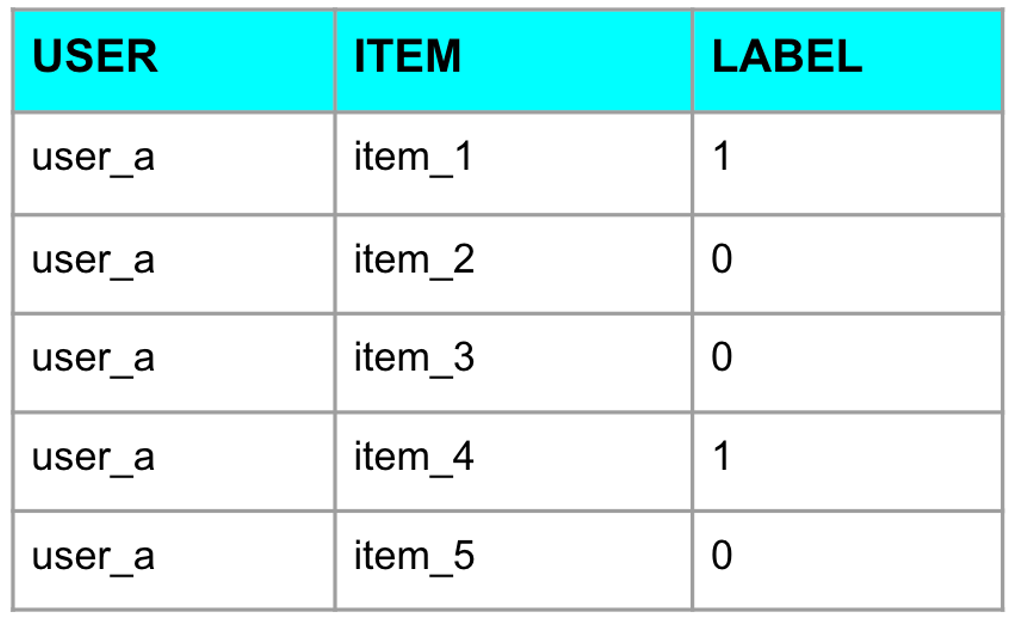
生成された一人の顧客のサンプルとラベルは下記のようになります。他の顧客についても同様に候補商品を生成します。
多様な戦略で候補を生成する
数百万の商品から数百まで絞り込むための最もシンプルな手法は、1つのルールで候補を生成することです。例えば、すべての顧客に直近の購入数Top-Nの人気商品を候補とする方法があります。しかし、この方法では、ファッション商品のレコメンドの当たる確率は高いものの、他の商品が全くレコメンドされない、人気商品に興味がない顧客も多いなど、すぐに限界に達してしまいます。個々の顧客に合致する商品をレコメンドするためには、多様な戦略で候補を生成することが不可欠です。
1970年代から研究されている協調フィルタリング[2]は、古い技術ながら長年の研究開発によって洗練され、初期の頃に比べて非常に高い精度でレコメンドができるようになったため、現在でもレコメンドシステムの主流技術として広く使われています。以下に、簡単な例を紹介します。
- 顧客:a・b・c・dの4人(dは推薦対象)
- 商品:1・2・3・4の4種
- 顧客購入履歴:a(1,3,4)・b(1,2,3)・c(1,3,4)・d(1)
- 商品同士の共起性(類似度)
- 1と2:1
- 1と3:3
- 1と4:2
- dに推薦する商品の順番(類似度の大きい順)
- 商品3 → 商品4 → 商品2

近年、協調フィルタリングから派生した技術が多く登場しています。筆者が実務で有効性を検証した中で、特におすすめしたいのは以下の3つの技術です。
- 行列因子分解(Matrix factorization)の一種である Bayesian Personalized Ranking (BPR)[3]
- 文章から単語の分散表現を獲得するWord2Vecをレコメンドシステムに適用した Item2Vec[4]
- ユーザノードとアイテムノードからなる2部グラフニューラルネットワーク(Graph Neural Network)の一種である Fast and Scalable Network Representation Learning(ProNE)[5]
これらのニューラルネットワーク技術を用いて商品IDあるいは顧客IDのembeddingを抽出し、近傍探索ライブラリ(faissなど)で類似度(cosine similarity、euclidean distanceなど)を計算することで、類似する候補商品を絞り込むことができます。さらにこれらと従来の協調フィルタリングを組み合わせることで、より高精度な候補生成戦略(アルゴリズム)を構築できることが知られています。
協調フィルタリング系の技術は強力ですが、データを深く掘り下げ、ドメイン知識も活用することで、さらに精度を改善できる余地があります。筆者がH&Mコンペで経験した例を紹介すると、顧客の過去の購入履歴を分析したところ、母親が子供の服を購入する場合には同じ商品をリピート購入することが非常に多く、また、同じ商品の異なるサイズや色を購入するケースも多いということが分かりました。この分析知見に基づいてルールベースの候補生成戦略を作成したところ非常に効果があり、協調フィルタリングを効果的に補完することができました。
業務知見の活用も大きな改善に繋がります。例えばファッション商品には独自のトレンド性があり、ヒット商品や、カラー・柄・素材などの流行の傾向が見られます。これらの業務知見をルール化することで、強力な候補生成戦略を構築できます。
こうして多様な戦略で候補を生成した後、各戦略の候補商品を統合します。この際、効果の高い戦略からは多めに候補を選択し、重複する商品は削除します。最終的に、顧客ごとに一定数の候補商品に絞り込みます。学習用データと予測用データで同じように候補商品を選択することで、データの分布が一致し、予測精度のずれを防ぐことができます。
本番システムとして実際に稼働させる場合、データ収集・処理システムの障害やデータドリフトの発生など、レコメンドシステムにダメージを与える可能性のある要素は少なくありません。多様な候補生成戦略を採用することで、単一障害点を避け、ダメージを最小限に抑え、レコメンドシステムの信頼性を向上させることができます。
バイアス対策
レコメンドシステムにおけるバイアスは推薦商品と実際購入商品とのずれを意味しており、主に学習データの偏りによって生じます。「顧客側のバイアス」と「商品側のバイアス」が考えられます。
顧客側のバイアスは、アクティブな顧客の購買履歴データが大量にあるために発生します。もしこれらのデータをすべて学習に用いると、アクティブな顧客の好みに偏り、非アクティブなユーザーに対してパーソナライズされた推薦が難しくなります。
対策としては、候補選択ステージで顧客ごとの候補商品数を一定に絞り、まずサンプルの偏りをなくします。さらに、顧客ごとの購買回数を重みとして利用します。購買回数が多い顧客ほど重みを小さくし、共起行列から計算された商品類似度スコアに重みをかけることで、候補商品のランクが変わり、全体の精度を向上させることができます。以下に、簡単な例を紹介します。
- 顧客:a・b・c・dの4人(dは推薦対象)
- 商品:1・2・3・4の4種
- 顧客購入履歴:a(1,2,3)・b(1,2)・c(1,4)・d(1)
- 顧客購入回数重み(購入回数の逆数)
- a:¼
- b:⅓
- c:½
- 重み付け商品同士の共起性
- 1と2:¼ + ⅓ = 0.583
- 1と3:¼ = 0.25
- 1と4:½ = 0.5
- dに推薦する商品の順番
- (1)商品2 (2)商品4 (3)商品3
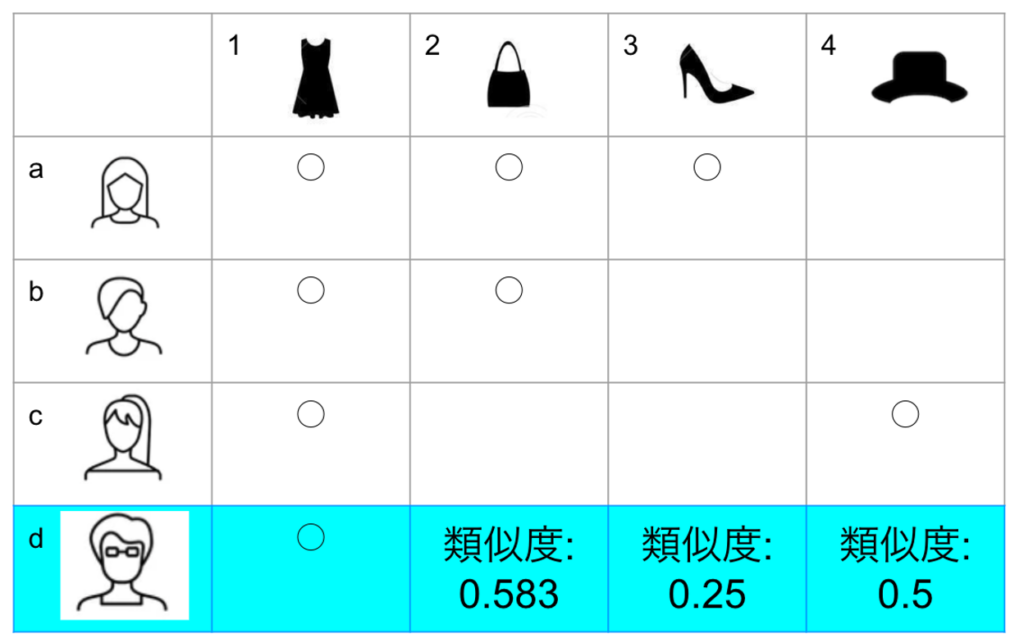
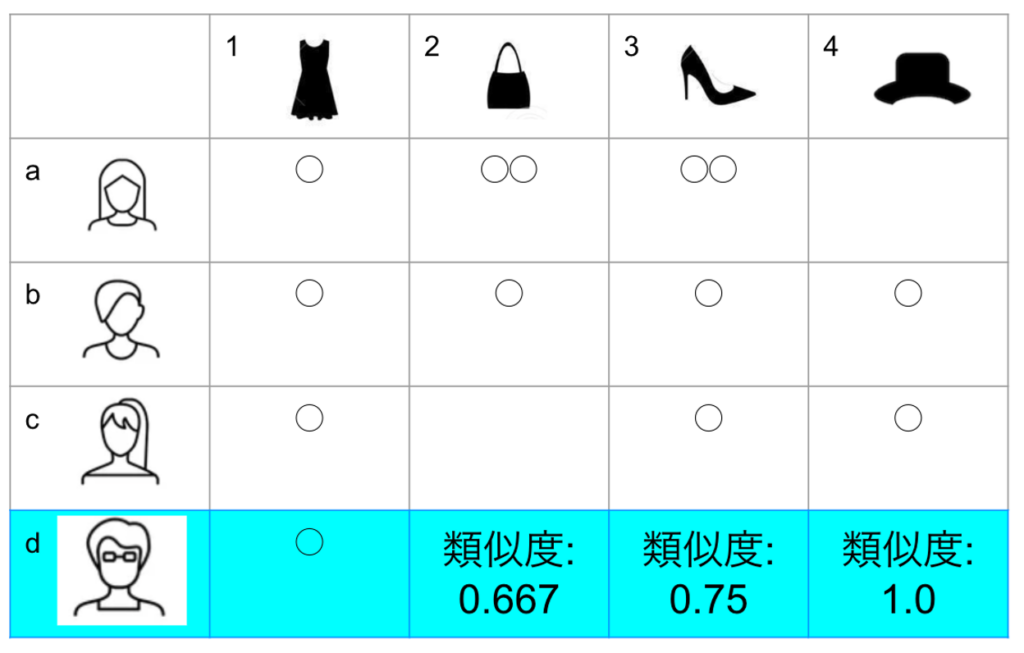
商品側のバイアスは、人気商品がよく他の商品と一緒に購入されるため、候補選択ステージで頻繁に選択される傾向があり、その結果、マイナーな商品が推薦される可能性が低くなる現象です。対策としては、商品の購入回数を重みとして利用します。購入回数が多い商品ほど重みを小さくし、共起行列から計算された商品類似度スコアに重みをかけることで、候補商品のランクが変わり、全体の精度を向上させることができます。以下に、簡単な例を紹介します。
- 顧客:a・b・c・dの4人(dは推薦対象)
- 商品:1・2・3・4の4種
- 顧客購入履歴:a(1,2,2,3,3)・b(1,2,3,4)・c(1,3,4)・d(1)
- 商品購入回数重み(購入回数の逆数)
- 2:⅓
- 3:¼
- 4:½
- 重み付け商品同士の共起性
- 1と2:⅓ + ⅓ = 0.667
- 1と3:¼ +¼ +¼ = 0.75
- 1と4:½ + ½ = 1.0
- dに推薦する商品の順番
- (1)商品4 (2)商品3 (3)商品2
バイアスの緩和対策以外にも、逆にバイアスを意図的にかけることで精度を向上させる手法があります。例えば、顧客の購買履歴において、商品同士の購入間隔が近いほど関連性が高いと考えられます。また、顧客が直近で購入した商品は、昔購入した商品よりも、次に購入する商品との関連性が高いと考えられます。これらの要素を重み付けすることで、候補商品の精度をさらに向上させることができます。
コールドスタート問題対策
購入や閲覧の履歴がある顧客と商品に対しては、嗜好を理解し、高精度なレコメンドを行うことができます。しかし、新規顧客や新商品が増えた際には、既存の履歴データが使えず、「コールドスタート(cold start)」と呼ばれる問題が発生します。
新規顧客のコールドスタート対策としては、年齢や地域などのデモグラフィック情報が分かれば、「同年代が好む商品」や「同地域で好まれる商品」などをレコメンドできます。もしデモグラフィック情報がなければ、「人気商品」のレコメンドも効果的ですが、ユースケースによって集計期間の最適化が必要となります。例えば、ファッション業界はシーズン性があるため、「シーズン人気商品」の方が妥当ですし、動画配信ではもっと短い期間で「直近1週間人気」などが妥当です。
新商品のコールドスタート対策としては、カテゴリ情報があれば、そのカテゴリを好む顧客に対して「同じカテゴリ内の新商品」をレコメンドできます。画像や文章がある場合は、さらに活用できる場面があり、「見た目が似ている商品」や「記述が似ている商品」をレコメンドすることもできます。新商品が何の情報も持たない場合は、商品の特性を理解し、人力でタグ付けする手段もあります。「同じタグ内の新商品」のレコメンドは、多くの業界で採用されています。
次稿では、ステージ1で選択された商品にランク付けを行うステージ2で使用される技法を詳しく解説します。
References
[1] https://www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations
[2]https://www.ibm.com/topics/collaborative-filtering
[3] https://arxiv.org/pdf/1205.2618.pdf
[4] https://arxiv.org/abs/1603.04259
[5] https://www.ijcai.org/proceedings/2019/0594.pdf
Get Started Today.