統計解析と機械学習:要因分析からの考察 Part 2
DataRobotでヘルスケア分野のお客様を担当しているデータサイエンティストの伊地知です。
本稿Part 1とPart 2では、要因分析に焦点を当て、以下5つの切り口で考察しています。
Part 1
- ステップワイズ法のように統計的仮説検定を繰り返す変数選択手法のリスク
- 変数選択プロセスにおけるパーティショニング手法の有効性
Part 2
- 伝統的な多変量解析手法によるアプローチと機械学習を用いたアプローチの適切な使い分け
- 機械学習を用いた変数選択アプローチの限界と、インサイトの安定性・再現性
- 要因分析におけるドメイン知識の重要性
伝統的な統計解析アプローチと機械学習の使い分けをどうするか?
Part 1で、要因分析の過程で多数の説明変数から本当に重要な少数の変数に絞り込む作業においては機械学習によるアプローチが有効との見解を示しましたが、では従来の統計解析手法はもう必要ないのでしょうか?
筆者はいくつかの理由(下記)からそのようには思いません。
- 目的変数(予測変数、応答変数、結果変数、アウトカム、エンドポイント)に影響を及ぼす要因をドメイン知識から丁寧に考えることは、これまでもこれからも必須のアプローチと言える。(特性要因図やマインドマップなどでドメイン知識を整理するとさらに有効)
- 要因分析目的では、「無計画に取られた大量のデータ」よりも「計画的に取られた少数のデータ」の方がより有用な情報を含む場合が多い。
- 要因分析目的では、まずドメイン知識から選択した1つあるいは少数の説明変数と目的変数の間の関係性を視覚化したり、統計的検定によってチェックすることは有効なアプローチである。
したがって、記述的な手法や推測統計学をベースとする伝統的な多変量解析手法も依然として使用できる場面はあり、「分析対象となる説明変数の数」に応じて使い分けるべきものと思います。例えば、回帰問題を例に挙げると下表のように、様々な手法を説明変数に応じて使用できます。
(Part 1で考察したように、説明変数の数が大きくなると統計的検定に基づく多変量解析を使った変数選択手法では多重検定のリスクが大きくなるため、目安として11個以上は機械学習を含む解析が使える、としています)

説明変数が増え、複雑なモデルを用いると解析に必要な計算リソースと計算時間も急激に増えていきます。そのため特に要因分析の場合は最初から闇雲に大量の説明変数を機械学習アルゴリズムに投入するよりも、ドメイン知識が多少ともあれば、それらを整理して有力な説明変数を洗い出し、まずは少ない説明変数で仮説を立てて検証する解析を行うアプローチが推奨されます。
また、なぜか「機械学習を使うなら取り敢えず説明変数を全部突っ込んでみよう」というやり方が巷で推奨されている感がありますが、要因分析に限って言えば、それは効率面であまり良くないと個人的には考えています。(前稿でも申し上げたように、要因分析は機械学習でやるにはレベルの高い課題です。正しく要因を絞り込むためにもドメイン知識を最大限に活用することが求められます)
本ブログ読者の中にもドメイン知識整理のために特性要因図(Fishbone Chart, Cause and Effect Diagram)やマインドマップをお使いになった方がいらっしゃると思いますが、機械学習を使って要因分析を行う時でも、事前にドメイン知識を整理して要因から結果にいたる機序(メカニズム)について仮説を立てておくと、問題解決までの時間の短縮に大きく寄与します。
「少数データ」や「横長データ」の分析における課題
DataRobot Japanでヘルスケア分野のユーザー様(主に創薬研究者や医学研究者)をサポートするようになってすぐに、筆者は「ヘルスケア分野では大量のデータを使ってモデリングを行うケースはそんなに多くない。むしろ少数のデータから何とか知見(インサイト)を得ようとされている分析者が多い。」との印象を持つようになりました。
1行が一人の患者さんのデータであったり、一つの実験結果や化合物のデータであるので、その一つのデータを獲得するためにも専門家(医師や創薬研究者)の多大な努力とコストが費やされています。したがって、それらのデータからできる限りの知見(インサイト)を引出したい、と考えるのは極めて当然のことと言えるでしょう。
多くても数千行、少ないものでは数百行のデータを弊社ではスモールデータと呼んでいます。スモールデータに機械学習を適用する際には留意する点がいくつかあり、DataRobotユーザー様からスモールデータを分析したいとのご相談をいただいた場合にはそれらのノウハウを指南しています。
他にもヘルスケア分野でよくご相談を受けるのが横長データです。これはレコード数nよりも説明変数の数pが大きいデータで、伝統的な線形重回帰分析では分散共分散行列の逆行列を計算できないため一意的な解を求められず、機械学習で解析的にアプローチするのが有効です。
スモールデータや横長データに対して機械学習アルゴリズムを回すためにパーティショニングを行うと、学習に必要なデータの情報量が相対的に少なくなって以下のような変動が問題になる場合があります。
- 検定データを最も精度良く予測するモデルがパーティショニング条件によって変わる
- 目的変数と強い関係性を持つとして選択される説明変数とその序列が変わる
特に後者の問題は、要因分析が目的の場合には解析結果の再現性が担保できなくなるわけですから看過できません。
推測統計学(例えば[2])の数理によると、ある母集団から抽出された標本(サンプルデータ)のデータ数が小さくなると、その標本から計算される統計量(例えば平均値や標準偏差)の信頼区間が広がる、つまり母集団の平均値や標準偏差の真値が存在する区間がより広範になることが知られています。有限の標本から計算されるパラメータには常にこうした曖昧さがあり、スモールデータになればなるほどその曖昧さの度合いが増す、と考えられます。この数理法則は機械学習においても全く同様です。
パーティショニング条件の変更による解析結果の変動
では、実際にスモールデータをDataRobotで解析し、ランダムシードの数字を変えてパーティショニングの条件(どのフォールドにどのデータが含まれるか)を変更した際にどの程度「特徴量のインパクト(Permutation Importance)」の解析結果が変動するのかを調べてみましょう。
弊社が製品デモの際に使用している「糖尿病患者さんの再入院予測」サンプルデータ(説明変数の数は約50個)から約980件を抽出し、ランダムシードの数字を3通りに変更しながらオートパイロットを行った結果を下表に示します。なお、「AVG Blender」は、複数の単独モデルを組み合わせた(このケースでは予測値の平均値をとった)アンサンブルモデル[3]です。
「特徴量のインパクト」が上位10個の結果
(AUCは交差検定結果)
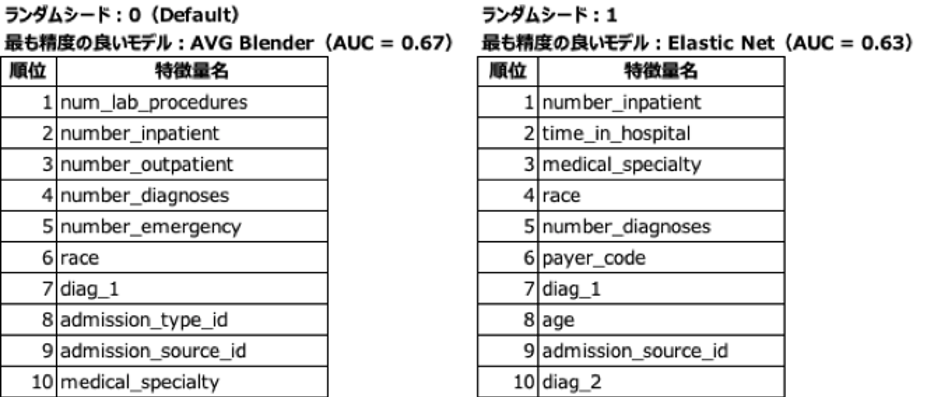

ご覧のように、
- 最も精度の良いモデル
- 精度(本例ではAUC)
- 特徴量のインパクト上位の説明変数(特徴量)
が全て変動していることがわかります。要因分析を行う目的でこのデータを解析したとしたら、私達はこの結果をどのように考えるべきでしょうか?
解析結果の頑強性(ロバストネス)を高める工夫
前章では、スモールデータのパーティショニング時にランダムシードを変更すると解析結果が変動することをご紹介しましたが、ではそれらの安定性を向上させ、要因分析のために有益な、再現性ある知見(インサイト)を得るためにはどうすれば良いでしょうか?
このトピックは昨年DataRobot Japanのヘルスケア担当データサイエンティスト達で検討し、さらにボストン本社のデータサイエンティスト達とも議論を重ねました。その結果、私たちは現在以下のアプローチを提案しています。
- 「元のサンプリングされた少量の学習データが潜在的に有するバイアス」の影響を、より頑強性(ロバストネス)の高いモデルを作成してできるだけ小さくする
- そのために、敢えて「多様な素性の機械学習アルゴリズムから作られたモデル単体を様々な方法で組み合わせたアンサンブルモデル」を作り、その結果を利用する
- 加えて、パーティショニング時のデータサンプリング条件(ランダムシード)を変更しながら何度も機械学習モデルを作って「特徴量のインパクト」を計算し、その結果を利用する
実際に、前章で用いたのと同じサンプルデータを用いて、以下の手順でDataRobotを動かした結果を示します。(なお外部からPythonスクリプトを使ってDataRobotを自動で動かしました)
- ランダムシードを10回変更して、オートパイロットを10回実施させるよう設定
- 各回とも、ホールドアウト0%でデータを7分割して交差検定実施
- 各回で、勾配ブースティング、ランダムフォレスト、Elastic Netなどの正則化回帰、ニューラルネットワーク、などアルゴリズムの素性が異なる機械学習モデルを組み合わせた数種類のアンサンブルモデルを生成(組み合わせ方も様々な方法を試す)
- 上記モデルの中で最も交差検定の精度が良かったものの「特徴量のインパクト」を計算
- 「特徴量のインパクト」の絶対値を説明変数(特徴量)ごとにまとめて、中央値の大きいものから順に図示(バイオリンプロット)
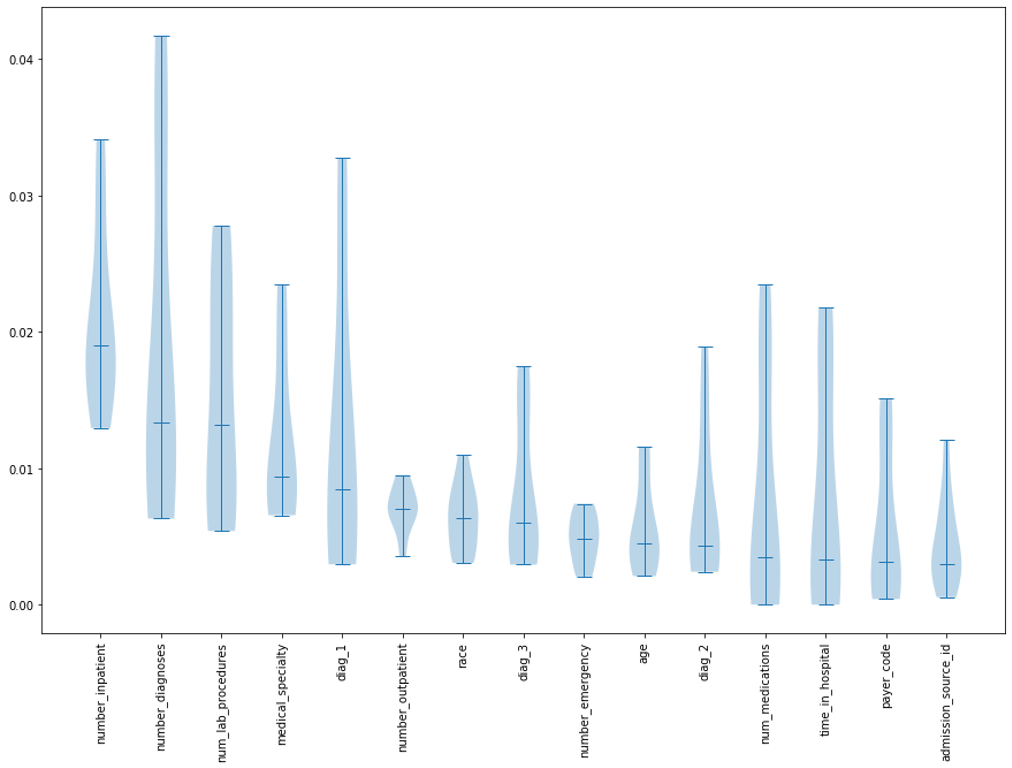
この方法は時間がかかりますが、DataRobotをPythonスクリプトで動かせば、上記データのサイズ(約1000行 × 約50列)なら、ユーザー様の標準的な環境では数時間程度で結果を確認できます。
要因分析におけるドメイン知識の重要性
さて、前章に示したバイオリンプロットをご覧になって、皆様はどのように感じられましたか?ランダムシードを変更しながらロバストなモデルを選んで「特徴量のインパクト」を計算しましたが、それでも結構ばらついているな、という印象を持たれた方も多いのではないでしょうか?
では上記のようなチャートが皆様ご自身のデータから得られたら、次にどのようなアクションをとれるでしょうか?いくつかの戦略が考えられます。
- ランダムシードの変更回数をさらに増やして、特徴量毎に「特徴量のインパクト」の情報量が増えると、「重要な説明変数」の中央値がもっと安定するかもしれません。
- 解析結果の曖昧さをできるだけ低減させようと思ったら、もしデータを低コストかつ短期間に取れるのであれば、推測統計学の教えに習って、データ量を増やすことも有力な手段です。目的変数との関係性が比較的強い説明変数が分かったのですから、これまでと同じ説明変数の項目ではなく、絞ってデータをとるなら、現実的かもしれません。
- 低コストで簡単に実験が可能なのであれば、明らかに重要そうな説明変数群(例えば上図であれば左から五番目まで)を取り上げた要因実験(直交表による一部実施法などを用いて)を行うのが良いかもしれません。
- 明らかに関係性が強そうな上位数件をドメイン知識の観点から検討して、「因果関係がある」と考えられたら、それら「要因」に対して対策アクションを実施することもできるでしょう。
産業界で現状改善のための要因分析を行っている人であれば、実際には上記Dのように、バイオリンプロットから「少数の重要な要因」をドメイン知識で抽出し、直ちに現状を変更するためのアクションに進む方針をとるケースが多いかもしれません。
以上、本稿で考察したことをまとめてみます。
- 要因分析において、機械学習を使えば従来の統計解析手法(記述的な手法や伝統的な多変量解析)は必要なくなるかと言えば決してそのようなことはない。分析対象となる説明変数の数によって適切に使い分けるのが望ましい。
- 品質管理分野で従来より利用されている特性要因図やCNX分類の手法はドメイン知識の整理を行うために非常に有用である。
- スモールデータや横長データを機械学習で分析すると、解析結果の変動が無視できなくなる場合がある。
- 素性の異なる機械学習モデルを様々な手法で組み合わせたアンサンブルモデルを使って解析結果の頑強性を高めるとともに、パーティショニングも変更させて、データの少なさに起因する変動があってもなお安定して重要な説明変数を見つける。
- 安定して重要な説明変数リストがわかれば、ドメイン知識から原因に気づき、対策アクションを取れる場合も多い。
2回のブログを最後までお読みいただきありがとうございました。統計解析と機械学習を要因分析に利用する場合の使い分け方や注意点について皆様のご理解が深まれば幸いです。
参考文献
[1] 山田秀, 片山清志, 富田誠一郎(2004):「TQM・シックスシグマのエッセンス」, 日科技連出版社
[2] 竹村彰通, 他(2015):「統計学Ⅱ:推測統計の方法 オフィシャルスタディノート」, 日本統計協会
[3] 門脇大輔, 他(2019):「Kaggleで勝つデータ分析の技術」, 技術評論社

90年代から医療用画像診断装置メーカーで統計解析や機械学習を使った品質改善(シックスシグマ )、要因分析、異常予兆検知、医療データ分析などに従事。2018年からDataRobot社のデータサイエンティストとしてヘルスケアチームをリードし、主に医療機関や製薬企業でのAIアプリケーション開発をサポートしている。また、伝統的な統計解析手法と機械学習各々の特長を活かした分析アプローチを研究し、各所で講演を行っている。
直近の注目記事
医療でのAI実践、病院で機械学習はどう活用されているのか(ビジネス+IT)
製薬業界の機械学習活用をプロセスごとに解説、がん治療をAIが助ける?(ビジネス+IT)
-
データとの対話:AIエージェントによる迅速かつ説明可能な回答
2025年4月16日| 推定読書時間 3 分 -
DataRobot Customer向けニュース(March)
2025年3月26日| 推定読書時間 1 分 -
DataRobotのPlaygroundにLLMをホスティングする方法
2025年3月11日| 推定読書時間 2 分
最近のブログ記事

