不正検知をAIで高度化
DataRobot で金融機関のお客様を担当しているデータサイエンティストのオガワミキオです。
ここ最近、金融機関での不正出金のニュースが世を賑わしています。今回の事件は多くのニュースでも取り上げられましたが、実際にはニュースで取り上げられない規模のものも含めるとほぼ毎日なんらかの不正が行われています。その被害額も凄まじく、例えば日本クレジットカード協会によると、2019年1年間のクレジットカードの不正利用額は273.8億円にも上ります。こちらはあくまで調査対象の44社で発覚しているクレジットカード不正利用の被害額です。
不正検知というと上記のように私が担当している金融業界では鉄板の AI テーマとなっていますが、実は金融業界以外にも様々な業界で不正テーマは存在しています。本ブログでは、様々な不正の種類に触れながら、実際に不正を防ぐための対策をどのように AI で実現していくか解説します。
業界別の不正
金融
盗む存在自体がお金ということもあり、外部・内部からの不正の件数は共にトップクラスに多い業界です。近年では、Fintech 技術によって様々な手段で金銭の移動を行えるため、多様な不正手段が散見されています。冒頭で触れた不正出金も、従来ビジネスを金融機関が一切変えていなければ発生しないものだったでしょう。ただ、従来ビジネスを一切変えない状態では、企業競争力は失われてしまうため、今の金融機関は、サービスのあり方を変化させながら不正から身を守るという二つの課題を並行して取り組む必要があります。
また直接お金を奪い取る不正だけでなく、そもそも不正に手に入れたお金を様々な金融機関を経由して洗浄する、マネーロンダリングという不正もあります。不正アクセスなどによってお金を奪い取る不正は被害者自身が発見し、申し出ることによって明るみに出てきますが、マネーロンダリングに関しては、声をあげる被害者はいないため、金融機関側が検知するしか方法がありません。アンチマネーロンダリング(AML)対策を怠ると巨額の制裁を受けることになるため、発生件数以上にこちらも重要な課題です。
流通・小売業界
流通や小売業界は実は金融業界と同じくらいに不正が多い業界です。換金性の高い商品(高級ブランド、PC パーツ等)を扱っている場合もあり、EC サイトなどデジタル化されたサービスはサイバー犯罪のターゲットになっています。またクレジットカードでの不正による購買では、本人確認(サインや 3D セキュア)が実施されていない場合には、その被害は加盟店側が保証する必要があるため、不正検知はビジネス上においても重要な位置付けとなります。
また近年は、サービス提供者が一対一で顧客と物品をやりとりするのではなく、出品者と購入者を繋ぐプラットフォームサービスも増えてきました。プラットフォームビジネスでは、出品者側で不正行為が行われていることも少なくありません。不正アクセスでの損害と違い、プラットフォームビジネスでの不正出品では、取引が成立すればプラットフォーマーとしては手数料が入ることによって利益を得ることになります。ただし、これらを放置するとユーザー側が不信感を募らせ、サービスブランドそのものを失うことにもつながります。来年1月には不正出品に関しての法案も提出される予定のため、オンラインのショッピングモールやフリマサイトは対応が迫られるでしょう。
メディア
メディアでは多くの収入を広告によって賄っています。直接のモノやお金を扱わないメディアにおいては外部からの不正アクセスによって盗むべきものはあまりありません。そんななかで最近メディアの不正として注目されているものに
広告プラットフォーム、代理店側からするとアドフラウドが発生していても損をするわけではないので、積極的に取り組むインセンティブが弱い状況です。しかし、広告主は意味のないボットなどによって余分な広告費を取られている状態であり、アドフラウドが蔓延してしまうと、広告主が広告を出稿しなくなり、長期的には広告全体の評判の悪化につながります。
通信
通信の不正というと通信の傍受というイメージが強いかと思いますが、電話サービスを乗っ取り、国際電話をかけることによって、契約者に高額な国際電話料金の請求がなされる不正も存在します。一見、電話サービスを乗っ取って電話をかけることはいたずら電話的な意味しかないないように思われますが、海外の電話会社と結託して、電話会社に上がる利益を犯人がマージンとして受け取るという仕組みになっています。電話会社と結託する必要もあり、ごく限られた国からの電話が該当するという癖があるものの、国際的な反社会勢力に資金が流用する案件であり、通信事業者に対して国からも対応が求められています。
ここまで見ていただいたように業界ごとに不正の種類は様々で、不正に対策する場合にはそれぞれの不正にあった対策が必要となります。この後は特に外部からの不正対策について紹介していきます。
不正対策と AI
不正に対処する有効な考え方は多層防御です。元々は軍事用語からきており、一箇所で守るのではなく、複数のエリアで防御を重ねる手法です。認証方法への対策、IPS/IDP や WAF によるネットワーク防御、通信の暗号化やデータの暗号化によってデータ自体を秘匿化し、権限分離による管理者乗っ取りへの対処、監査やモニタリングによる監視と、多重の対策によって不正に対処する必要があります。暗号化や認証に関しては導入するかしないかの2択であり、これからも多くの企業で導入は進むでしょう。ただ、導入すれば終わりとならないのが、モニタリングにおける検知ロジックです。
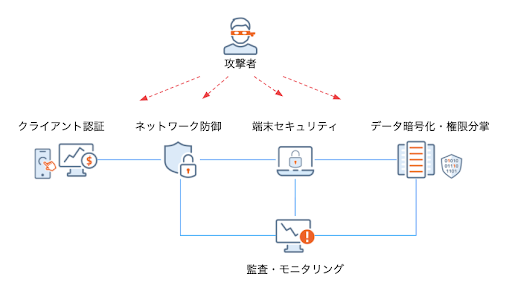
検知ロジックでは、不正をどれだけ検知できているかだけでなく、正常なトランザクションに対しては正しく正常と判定できているかも重要となります。極端な話、全てのトランザクションを不正と見做してしまえば、不正を見逃すことはありませんが、正常なトランザクションも止めてしまい、サービスとして成り立たないでしょう。そのため、検知ロジックではどれだけの偽陽性(不正でないのに不正と判定してしまったもの)と偽陰性(不正であったのに検知できなかったもの)が発生しているのか両方に目を配る必要があります。
検知ロジックは多くの場合、ルールベースで稼働していて、そのルールは初期登録されているものもありますが、自社のトランザクションや過去の不正の傾向に合わせて経験則で更新されているケースもあります。最近はトランザクションから取得できるデータも数千を超える場合もあり、不正手法の変化も早いことから、人力でのルール探索とメンテナンスは大きな負荷となっています。
AI はまさにこの検知ロジックで効果を発揮します。大量のデータから複雑なモデルを高速に作成し、不正検知モデルとして利用することによって、日々変化する不正に対して対応することができます。ただ、AI を導入すればワンパターンにうまくいくものではなく、不正の構造を見抜き、正しいアプローチと運用を組み合わせることによって AI の効果を最大化することが必要です。
対象となる不正が明確な場合:教師あり学習
不正検知の中でも取り分けアプローチのしやすい不正としては、一件ごとのトランザクションにおいてそれが不正か不正でないかが明確なケースです。不正の被害が明確で、不正として報告するインセンティブが高いものが該当します。例えば、クレジットカードの不正利用や EC サイトでのアカウント乗っ取りなどは、更なる被害の防止と補償金をもらうために、不正の被害にあった本人が正しく不正と報告するインセンティブが働き、結果として正しいラベルが付けられます。
正しくラベル付けされている状態なので、教師あり学習が効果的です。ポイントとしては、不正の件数が100件を下回る場合には、なかなかパターンを AI が学習できないので、不正の定義を広げて対応しましょう。不正の定義を広げる場合には、最終的な不正となってしまったものだけでなく、調査で不正と判断されて事前に取り除かれたものも不正ラベル側に含めていきます。件数が少なくとも諦めずに、最終的に被害を受けてしまったもの以外もターゲットに含めることによって AI の解きやすいテーマに変えることができます。
不正が明確であったと思っていた場合でも、AI モデルが予想外に大きく外してしまった(AI モデルは高確率で不正と判定もデータ上は正常だった)トランザクションには是非注意を払いましょう。実は被害者自身も不正を見逃していて、ちゃんと見直すと実際には不正だったということはよくあることです。
対象となる不正が未知な場合:異常値検知、半教師あり学習、プロキシターゲット
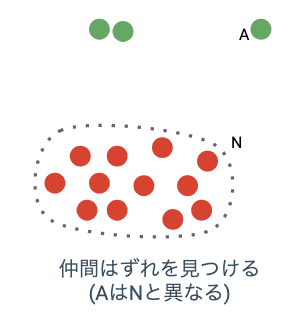
どれが本当の不正なのか網羅できていない場合には、違ったアプローチが必要です。マネーロンダリングや一部の不正出品などは犯人が不正であることを自ら名乗り出ることはなく、クレジットカード被害のように関係者も被害を直接受けていないことから、自然に正解ラベルがつくことは期待できません。そのため、企業側が積極的にラベリングする必要があります。その際に、既存のトランザクションの大多数がチェックできておらず、どれが不正か不正でないのかわからない場合には、異常検知アルゴリズム、半教師あり学習やプロキシとなるターゲットを利用していきます。
異常検知アルゴリズムでは、元のトランザクションに対して異常なトランザクションを見つけることができます。未知の不正であっても、それが今までにないトランザクションの傾向を示していた際には捉えることができるでしょう。ただ、あくまで異常なトランザクションに反応するだけなので、未知の不正がある程度の塊になっていて正常なトランザクションと混在するケースや、異常なトランザクションだからと言って不正とは限らないトランザクションも多いことから、精度は高くありません。他の手法と組み合わせて利用することがおすすめです。
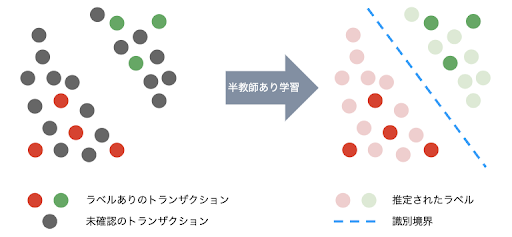
半教師あり学習では、数件の正解ラベルを増幅させて学習を繰り返す手法になります。手元の数十件の不正が見えていて、残りのトランザクションが手付かずの場合に、まずは数量のターゲットを元に教師あり学習を実施します。そこから作成したモデルで元のデータへのスコアリングを行い、不正リスクが高いと判定されたものを改めて正解データとしてアップデートしてモデリングを実施します。半教師あり学習においてはどの閾値からを正解ラベルとするのかと学習を回す回数には試行錯誤が必要ですが、全トランザクションを到底チェックしきれない場合には、人力で正解ラベルを作り直すに比べて遥かに有効な手段です。
もう一つのプロキシのターゲットを利用する手法は、対象となる不正に対してのドメイン知識がある場合にはとても有効な手段となるでしょう。不正となるトランザクションの最終的な二次影響をドメイン知識を元に決め、モデリング結果を調査することによって見つけていきます。
例えば、手数料を抜き取るタイプの不正契約に関しては、途中までの手数料を確保した後に高い確率でキャンセルされる構造が成り立つ場合、キャンセル率の高い取引をターゲットとします。不正と関係なしにキャンセル率が高い傾向の契約もあるかもしれませんが、明らかに不自然な確率でキャンセル率が高いパターンがあったり、やけに複雑なロジックでのみスコアが高くなる場合には要注意です。不正を行う側もシンプルな方法では既存のルールベースの仕組みに引っかかってしまうため、特別なプロセスで不正を働くケースがあります。そのプロセスは往々にして遠回りで複雑なプロセスを踏みやすいため、やけに複雑な条件下でターゲットの予測スコアが高い時には不正なトランザクションかもしれないという疑いを持つことはとても重要です。
プロキシのほかの例としては、優良アカウントをターゲットにすることもあります。エンゲージメントはほぼゼロなのに絶対に解約しない、なぞの優良アカウントが見つかった場合には何らかの不正のための仕込みアカウントであるケースがあります。この場合には、振る舞い的には優良アカウントゆえに、企業としてはそのまま放置したくなりますが、不正取引の温床になる可能性もあり、企業ブランドを著しく損なう場合やマネーロンダリングの場合には制裁金の問題に繋がるため、積極的な対処を行うべきです。
AI 不正検知モデルのデプロイ
デプロイ手法
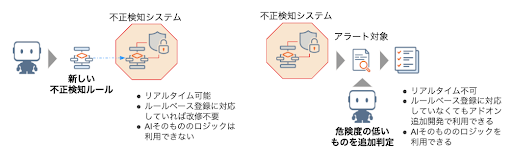
従来からある不正検知のシステムが、データ収集、リアルタイムトランザクションの監視、アラート生成機能、高可用性を持っている場合には、その資産を有効活用することが効果的です。従来システムに相乗りする方式では従来システムの満たす要件をそのままに AI モデルをデプロイすることが可能です。そのシステムが API 接続可能であれば、API によってスコアリング結果を読み込むことがもっとも AI の精度をそのまま活用でき、簡単でしょう。ただトランザクション頻度が多いと、API 接続では計算が間に合わないという問題があります。この様な要件を持つ不正検知システムではルールベースが採用されていることが多いため、AI から有用な特徴量を抜き出す作業やモデルをルールに書き直して対応します。
API 接続もルールベースの更新登録もできない場合には、検知タイミングを2段階にすることによって対応可能です。AI モデルを既存システムのアドオン的に動かすイメージですので、リアルタイム性は失われますが、現行の不正チェック自体がシステムと人力の合わせ技などで行っている場合に、システムと人の間に追加で配置することによって人の工数を大きく削減することが可能です。アドオン的に外だしすることからリアルタイム性を必要とするオーソリなどには利用できませんが、AML 対応には実際によく取られるデプロイ手法になっています。
継続的なモデリング(MLOps)の重要性
不正モニタリングで AI を使う最大の利点は精度ではなく、継続的なモデリングにあります。多様な攻め方を実施できる犯罪者側は既存手段が防がれたとしても、新たな手段を思いついては新しい攻撃手段で不正を働くでしょう。過去データから学ぶ AI においても一発目の不正を防ぐということは至難の技ですが、いかに早く同類の手口を止めることができるのか、またはすでに攻撃されてしまった過去の取引の中から不正に該当するものを洗い出すという行為はとても重要です。AI は人力でパターンを探し出すという部分の精度をあげるだけでなく、大幅に作業時間を短縮することができるので、継続的に素早く検知ロジックをアップデートすることができるようになります。
またモデリング時間短縮だけでなく、不正のパターン、全体のトレンドが変わったことに早く気づくことも必要です。そこで重要になってくるのが、既存の運用しているモデルの精度変化と、トランザクションの性質自体が変わっているかを確認するためにデータドリフトを監視することです。
精度が悪くなっている場合には、新しいパターンの不正が発生して、既存の検知ロジックではカバーできなくなっている状況が考えられます。この場合には、新しい不正ラベルを元に再度モデリングを実施するべきです。精度の変化は悪くなっている場合はもちろんですが、よくなりすぎている場合も注意が必要です。この場合には捉えられていなかったタイプの不正が減ったのか、捉えられやすいタイプの不正が増えたという状態です。ただ、わざわざ不正を行う側の視点に立てば、まだ通用する手段をやめて、バレやすい手段を増やすメリットはありません。攻撃手段が変わってそのサービス自体がターゲットにされなくなったということもありますが、最悪のケースとしてはラベル化できてない(データ上は正常と判定されている)不正が増えている場合です。この場合には、上記に記載した不正タイプが未知の場合の手法を再度繰り返していく必要があります。
次にデータドリフトに注目する理由を解説します。データドリフトとは、学習時のデータ分布からデータ分布が変化したことを意味することです。データドリフトは全体のトランザクションの統計情報となるので、多くとも数パーセントから1%以下しかならない不正トランザクションのパターンが変化しただけでは影響はあまり出てきません。ただデータドリフトが発生していると不正検知モデルの偽陽性が増えている可能性があります。最近だとキャッシュレスの推進施策と新型コロナウイルスの影響から、老若男女関わらずキャッシュレスを利用する状態です。このような状況で従来の不正検知モデルを利用することは正常なトランザクションもこれまでにない動きということで検知モデルが不正と誤判定する可能性があります。偽陽性を抑えるためにも、データドリフトが発生した場合にも検知モデルの洗い替えは必要です。
DataRobot での不正検知へのアプローチ
DataRobot AutoML では、データサイエンスに必要な数学的な特徴量エンジニアリングやアルゴリズム選定、ハイパーパラメータのチューニングなどを DataRobot に任せることができます。そのため、不正検知の担当者は、検知ロジックを高精度にしながら、不正そのもののメカニズムや検知前後の対応に労力を割くことができるようになります。
またこれまでデプロイ手法において直接 AI モデルを使うパターンとモデルをルールベース化する2パターンを紹介しましたが、DataRobot ではいずれのパターンも実現できる仕組みが存在します。直接 AI モデルを使うパターンは通常の予測と変わらないので、普段取り上げられないルールベース生成機能など不正検知と関わり深い機能を中心に紹介します。
Hotspot
Rulefit 系のモデルを作成することによって、大量のルールが自動的に生成されます。全てのルールにおいて、該当するトランザクションの比率とそのルールに該当した際のターゲットが陽性となる確率が算出されるため、有効なルールを簡単に見つけることができます。またルール同士の近さを可視化する機能も合わせているので、どのようなタイプの不正が蔓延しているのかも視覚的に捉えることができます。
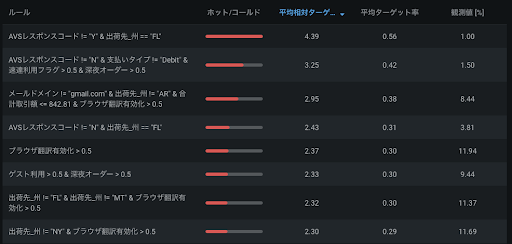
格付表
DataRobot では、高精度にチューニングした一般化加法モデルを格付表として出力することができます。交互作用項も自動的に検出するものも実装されているため、特定の特徴量の組み合わせが不正に影響するというのも見つけられる可能性があります。詳しくはこちらのブログをご参照ください。
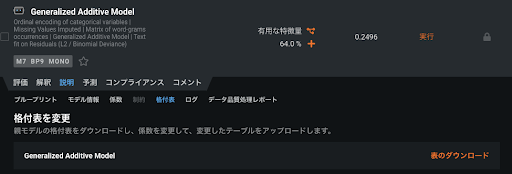
Eureqa
遺伝的アルゴリズムである Eureqa は最終出力が一つの数式になります。設定によっては数十万を優に超える数式の中から、最も当てはまりの良い一つの数式型のモデルを算出することができます。最大の特徴は一つの数式となることからスコアリング時間が相当に早いところです。リアルタイム性が強く求められる不正でのルール検知では大いに役立つ可能性があります。こちらも DataRobot Prime と似た形で、数式の複雑さがどれだけ精度に寄与するのかを可視化し、選ぶことができるようになっています。
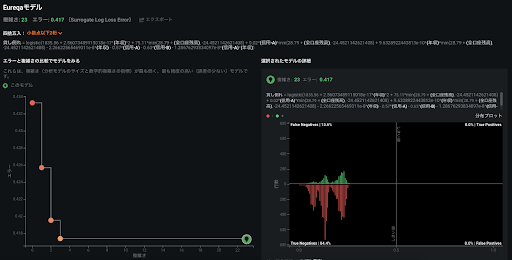
異常検知アルゴリズム
DataRobot では、ターゲットありの異常検知とターゲットなしの異常検知を提供していますが、特に不正検知ではターゲットありの異常検知設定を利用します。この場合、ターゲットを除いた特徴量での異常検知モデルが作られますが、元のターゲットに照らし合わせた際の精度も確認することができるため、異常なトランザクションが過去の不正とどれだけ関連があったのかを確認することができます。異常検知アルゴリズムとしては、何をもって異常とするのかが難しい分野でもありますが、DataRobot では複数の異常検知アルゴリズムをクリック一つで試せてしまうので、相性のよい異常検知アルゴリズムを探すことも複数の異常検知アルゴリズムと通常の教師あり学習のアルゴリズムを合わせて利用することも簡単に実現可能です。

MLOps 機能
DataRobot では、通常のシステム運用で必要な API のステータス確認機能だけでなく、MLOps で必要となる精度監視系の機能、データドリフト検知機能も設けています。
精度監視の機能に関しては、予測時の結果と後に判明した実測値の値を紐づけて管理することができます。API での利用であれば予測値は直接 DataRobot に保存されるので実測値をアップロードしていけば時間ごとの精度の変化を確認することができます。API を使わない時にはエージェント方式で同様の機能を利用可能です。
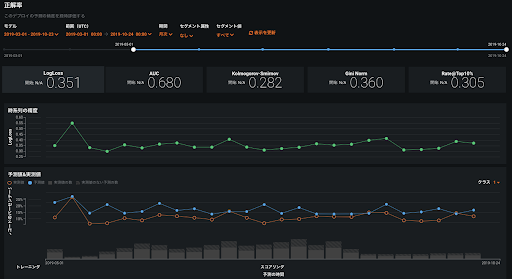
データドリフト機能に関しては、学習時から特定の時期の範囲でドリフトがどの特徴量で発生しているかを確認することができます。特にモデルが重要視している特徴量が大きくドリフトしてしまうとモデルが従来のパフォーマンスを発揮できなく可能性があるため注意が必要です。DataRobot のデータドリフトタブは精度監視機能と同様に API 利用では自動的に予測値の統計情報を保存し、学習時と予測時のデータ分布の違いをモデルが重要視している特徴量の軸との発生状況の2軸でプロットし、それぞれの特徴量ごとに詳細なドリフト発生状況を見れるようになっています。こちらもエージェント方式での利用も可能です。
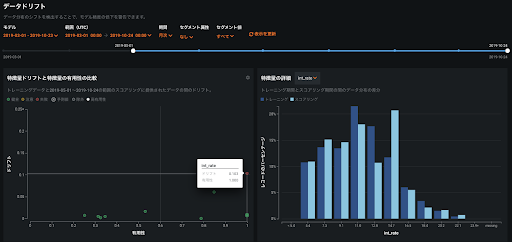
DataRobot ではこれらの MLOps 機能自体を API で抽出できるため、モデルの劣化機能状況自体をアラートとして取得することができます。
まとめ
既存システムとの共存によって成果を発揮するケースや新しい形で不正を止めていくという様々なアプローチを紹介しました。注意いただきたいのは、AI が得意な部分は検知ロジックの部分であり、AI だけを導入すれば必ず不正が防げるというものでないことと、完璧な不正検知ロジックなどは存在しないということです。最新の不正の傾向も加味しながら、人と AI が共存してこの脅威に立ち向かう必要があります。実際に AI を検知ロジックに導入し、年間で大きな ROI を出している企業は少なくありませんので、是非 AI での不正検知の高度化を積極的に進めていただければと思います。

DataRobot Japan創立期に立ち上げメンバーとして参画。インフラからプロダクトマネジメント業、パートナリング業までDataRobotのビジネスにおけるあらゆる業務を担当し、ビジネス拡大に貢献。その後、金融業界を担当するディレクター兼リードデータサイエンティストとして、金融機関のお客様のAI導入支援からCoE構築支援をリード。2023年より、全てのお客様における価値創出を実現するため、日本のAIエキスパート部門の統括責任者に就任。豊富なAI導入・活用支援のノウハウから公共機関、大学機関における講演も多数担当。2022年より一般社団法人金融データ活用推進協会(FDUA)における企画出版委員会の副委員長に就任。
-
データとの対話:AIエージェントによる迅速かつ説明可能な回答
2025年4月16日| 推定読書時間 3 分 -
DataRobot Customer向けニュース(March)
2025年3月26日| 推定読書時間 1 分 -
DataRobotのPlaygroundにLLMをホスティングする方法
2025年3月11日| 推定読書時間 2 分
最近のブログ記事

