RAG(Retrieval-Augumented Generation)構築と応用|生成AI×DataRobot活用術
はじめに
DataRobotで製造業/ヘルスケア業界のお客様を担当しているデータサイエンティストの長野です。技術的には生成AI領域を担当し、日本市場での生成AIプロダクトの導入と顧客支援を担当しています。
本記事では、生成AIの中でも特に注目を集めている技術領域の一つである「RAG(Retrieval-Augmented Generation)」に焦点を当てつつ、DataRobotで実現できる内容について解説させていただきます。
なお、本記事と関連するウェビナー「生成AI最前線:DataRobotを用いた実践RAG構築」では、実際のデモンストレーションを交えながらRAGに関して解説していますので、合わせてご確認いただければ幸いです。
LLMの活用パターンとRAG(Retrieval-Augumented Generation)の立ち位置

RAGについて踏み込む前に、ビジネスにおける大規模言語モデル(Large Language Model、以下LLM)の活用パターンを整理すると、大きく以下の3つに分けることができます。
活用パターン1. 事前学習済みLLM
このパターンでは、ChatGPTなどの既存の生成AIサービスやGPT3.5などのLLMをそのまま利用することを指します。導入コストが低いことがメリットとして挙げられます。執筆時点で多くの企業ではこのパターンでのLLM活用は進んでいると感じます。
活用パターン2. 検索拡張型LLM
検索拡張型LLMは、ユーザーからの入力に対して関連する情報を元に検索し、その結果をもとに回答を生成します。本記事の題材であるRAGがこのパターンに該当します。執筆時点でOpenAI社のgpt-4-turbo-previewは2023年12月、gpt-3.5 turboは2021年9月までの学習であり、最新の情報や社内文書も学習していません。そのため検索拡張型LLMが、社内文書や最新の情報を踏まえたLLMを構築する手法として注目を集めています。
活用パターン3. 追加学習/自作LLM
最後に、独自のニーズに合わせてLLMを追加学習させたり、オリジナルのLLMを開発するアプローチがあります。個々のユースケースに柔軟に対応させたLLMの開発ができる一方で、多くの企業にとってはまだまだ技術的ハードルの高い手段です。
この3パターンの中で、RAGが導入コストとユースケースとのマッチ度の観点で多くのユーザーが取り組まれている技術となります。
RAG(Retrieval-Augumented Generation)の課題
前章で解説したようにRAGの構築は比較的簡単に導入できる手法であると認識されていますが、弊社が実際にRAG開発に取り組まれている企業にヒアリングすると成果が出ていないケースも見受けられます。以下はその理由をまとめたものです。

課題1: テーマに対して技術的な課題を適切に捉えられていなかった
- 社内の文章を入れたら簡単にRAGが構築できると考え、あまり調査せずに中身がブラックボックスなツールを選定してしまう。
- Pythonライブラリを用いたRAG開発を試みるが、開発できるメンバーの不足や運用監視に苦労している。
課題2: RAGを構築できる人材が少なくスケールしない
- ユースケース毎に多くのRAGを開発する必要があるが、RAGの開発と運用監視の観点でプロジェクトが進んでいない。
課題3: 本番環境を想定した検証ができていなかった
- PoCを実施した結果、良さそうな結果は得られたが、本番導入を想定したハルシネーション対策や運用時の死活監視や精度監視までは確認できていない。
DataRobot生成AI機能を使うメリット

それでは、DataRobotの生成AI機能がこの問題に対してどのようにアプローチしているのかを以下の3つの視点からご紹介します。
DataRobot生成AI機能のメリット 1: RAGの開発
まず初めに、RAGが開発できないことには始まりません。DataRobotでは迅速なRAGの開発を実現できますが、この開発パートに関しては、後ほど詳しく解説します。
DataRobot生成AI機能のメリット2: API化/Webアプリ化
AIモデルを使って予測分析を行うユースケースでは予測結果のインサイトの取得も価値に繋がることが多く、実際に筆者が担当している製造業のお客様では要因分析のテーマでDataRobotをご活用されているケースも多くあります。要因分析のテーマでDataRobotをご活用されているお客様が非常に多くいます。一方で、生成AIのテーマでは、想定していた回答を返すだけではなく、実際にシステムへの組み込みやアプリケーションの開発まで求められるケースが非常に多いです。DataRobotではAPIによるシステム連携やStreamlitのDataRobotへのホスティング機能が充実しており、生成AI特有の課題に対しても十分にカバーできます。
DataRobot生成AI機能のメリット3: 運用監視とガードレール
予測AI/生成AIを問わず、あらゆるAIモデルはそのモデルを構築した時点から時間が経過すると精度パフォーマンスが劣化します。したがって、RAGを構築し生成AI機能を利用したアプリケーションを稼働させる際には、その精度パフォーマンスをはじめとする様々な品質指標を監視する仕組みも併せて稼働させることが必須です(予測AIモデルの運用を監視する仕組みはMLOpsと呼ばれていますが、生成AIシステムではLLMOpsと呼ばれています)。特に生成AIシステムでは、消費トークン数をトラッキングする、毒性のある単語/文章をガードレールにより弾くなど、様々な品質指標を設定してパフォーマンスを監視しながら、入力プロンプトの単位で適宜アクションをとる必要があります。DataRobotはこれらの要件に答えることができるAIライフサイクル・マネジメントプラットフォームです。
DataRobotを用いたRAG(Retrieval-Augumented Generation)構築
それでは、実際にDataRobotの画面を用いてRAGを構築してみます。NextGenインターフェイスでは予測AIと生成AIを同一のインターフェースから開発することができます。本ケースのようにRAGを構築する際は「データ」、「ベクターデータベース」、「プレイグラウンド」のタブを活用します。

データタブ:データの投入
RAGを構築する際に必要となるデータを投入します。2023年3月現在はtxtファイルとPDFファイルに対応しており、これらのファイルをZIPファイルにまとめて投入します。今回は、GPT3.5をそのまま使うと回答できないDataRobotの製品マニュアルをアップロードしてみました。
ベクターデータベースの構築
次にベクターデータベースを構築します。ベクターデータベースと聞くと構築が非常に困難に感じるかもしれませんが、DataRobotでは一つの画面上で簡単に設定することができます。主要なオプションを以下で解説します。
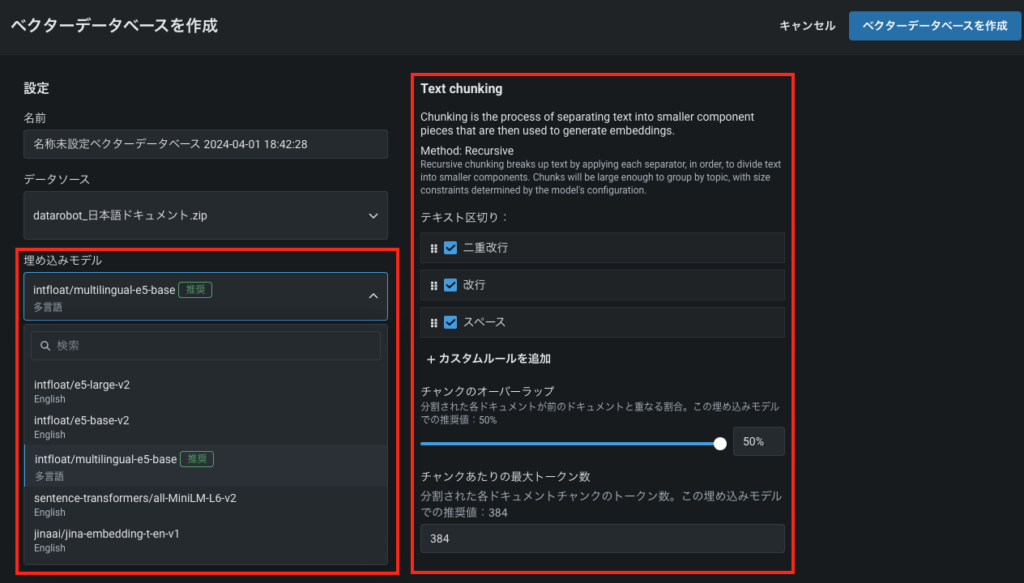
①埋め込みモデル
RAGに使用するデータを選択した後、「埋め込みモデル」タブをクリックし、今回使用する埋め込み(Embedding)モデルを選択します。Embeddingとは、後述するチャンクをベクトル情報に変換するモデルのことを指します。執筆時点では日本語も含む多言語対応モデルであるinfloat/multilingual-e5-baseなど、5種類のEmbeddingモデルから自由に選択することができます。埋め込み(Embedding)モデルの選択は回答の精度や出力のレスポンスに影響しますので、RAG開発フェーズで様々なモデルを試せることが重要です。infloat/multilingual-e5-baseのケースではチャンクを768次元のベクトル情報に展開します。これがベクターデータベースと呼ばれる理由です。
②チャンキング
チャンキングはテキストを分割する方法を指しており、一つ一つの固まりをチャンクと呼びます。一つ一つのチャンクをどのように分割するかによって同じデータでも得られる情報が変わります。極端な例ですが、文章を文単位の小さなチャンクに分割すると文脈の情報が欠落してしまいますし、反対に長文を一つのチャンクにすると本当に取得したい情報が得られないリスクがあります。チャンクを区切った際に、前後の文章も含める度合いをチャンクオーバーラップのパラメータで制御します。値を小さくしすぎると文脈が途切れてしまうリスクがありますが、大きくしすぎると、ベクターデータベースの容量が大きくなり、レスポンスタイムに影響します。
プレイグラウンドによる検証
ベクターデータベースの構築が完了したら、RAG構築の最後にプレイグラウンドを用いた実験を行います。プレイグラウンドは名前の通り、試行錯誤が非常にしやすい検証環境となっています。ここでは設定可能な主要パラメータについて解説します。
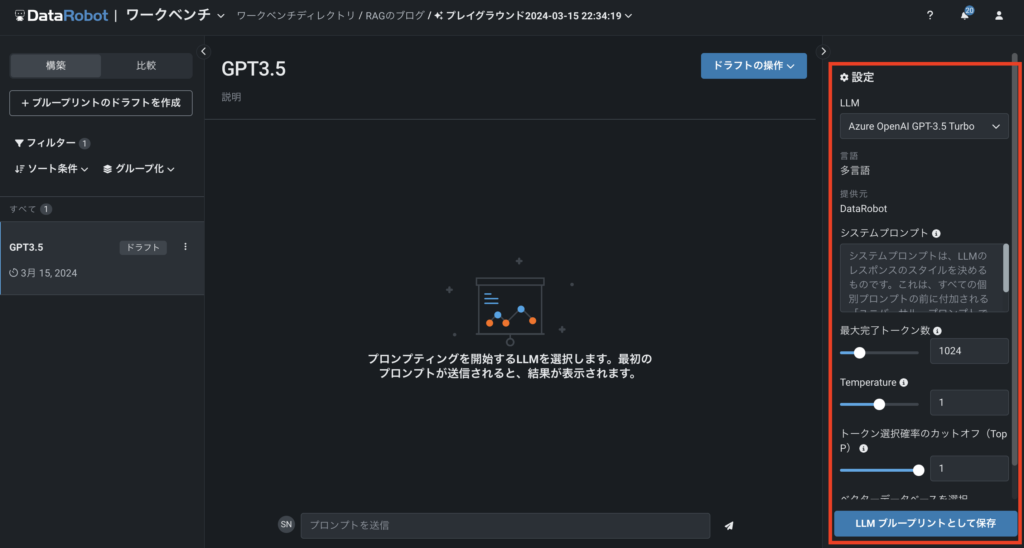
①LLM
LLMでは、DataRobotにプリセットされている多様なLLMの中から、自由に選択することができます。現在、選択肢としてGPT-3.5系、GPT-4系、AmazonTitan、Google Bisonの6種類が用意されています。さらに、皆様の会社で独自に契約されているLLMを、この選択肢に追加することも可能です(Bring-Your-Own LLM、以下BYOLLM)。
セキュリティポリシーの観点から、社内契約のLLMのみを使用可能な場合でも、BYOLLMのみをプレイグラウンド環境で利用する設定により、柔軟に対応することができます。これにより、各社のセキュリティ要件を満たしつつ、LLMの性能や特性を比較検討し、最適なモデルを選択することが可能になります。
②システムプロンプト
システムプロンプトは、通常のプロンプトとは異なる機能であり、RAGやLLMに対して、特定の役割や振る舞いを設定することができます。これにより、APIコストの最適化やエンドユーザーのニーズに合った回答の生成が可能になります。
ビジネスシーンにおいて、システムプロンプトを効果的に活用することで、例えば以下のようなメリットが期待できます。
トークン数の節約:「100文字以内で回答してください」といったプロンプトを設定することで、回答の文字数を制限し、トークン数を抑えることができます。
エンドユーザーのニーズに合った回答の提供:「箇条書きで答えてください」などのプロンプトを用いることで、情報を簡潔にまとめ、読みやすく構造化された回答を生成できます。
③ベクターデータベースを選択
こちらのタブを使用することで、RAGに用いるベクターデータベースを選択することができます。構築済みのベクターデータベースを選択することで、LLMに対して追加の文脈情報を提供し、より正確で関連性の高い回答を生成することが可能になります。もちろん、ベクターデータベースを選択しない場合は、素のLLMやシステムプロンプトのみを付与したLLMとして検証することも可能です。
RAGは一見すると複雑な技術に思えるかもしれませんが、DataRobotを使えば、実際の構築のプロセスは非常にシンプルになります。必要なデータを用意し、ボタンを数回クリックするだけで簡単にRAG用のベクターデータベースを作成することができますので、専門的な知識がなくても、誰でも手軽にRAGを活用することが可能となります。
RAGの設定が完了したので、実際の性能を確認してみましょう。画面の左側にはRAG(GPT3.5-Turbo + ベクターデータベース)の結果が、右側にはGPT-3.5 Turboのみの結果が表示されています。この比較機能を使うことで、データベースの有無による回答の違いを簡単に確認することができます。
DataRobotでは、最大3種類のブループリントを同時に比較することが可能です。これにより、異なるLLMやデータベースの組み合わせによる性能の違いを一目で把握することができます。
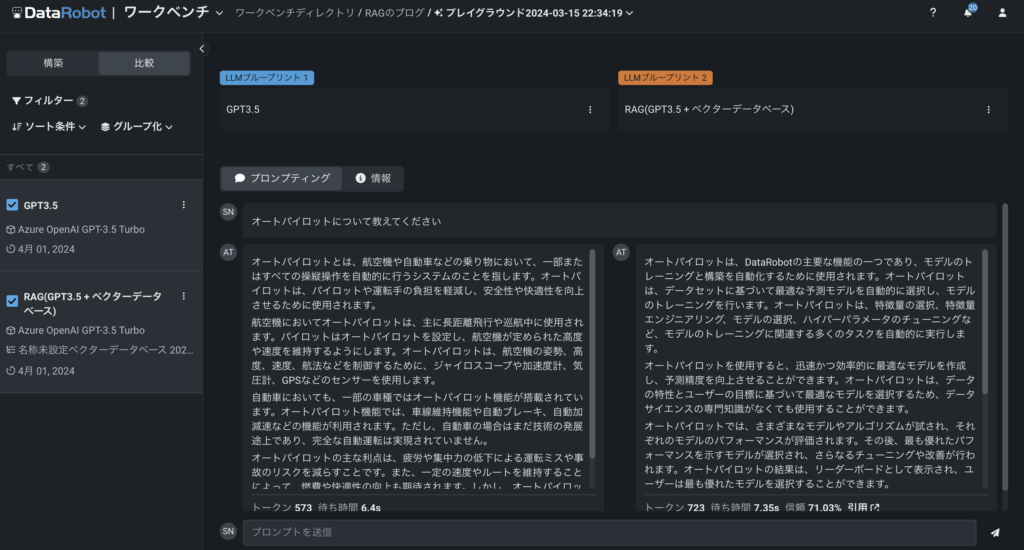
今回、「オートパイロットについて教えてください」というプロンプトを使って、素のGPT-3.5とRAGとの性能を比較してみました。その結果、両者の回答には明確な違いが見られました。
素のGPT-3.5では、ベクターデータベースを使用していないため、一般的な「オートパイロット」の概念について説明しています。つまり、自動運転技術や航空機の自動操縦システムなど、辞書的な定義に基づいた回答が生成されています。一方、RAGを構築したケースでは、DataRobotの文脈に基づいた回答が得られました(オートパイロットモードはDataRobotのモデリングモードの一つです)。
この比較結果から、RAGがタスクに関連する情報を適切に取り込み、文脈に沿った回答を生成できることが確認できました。データベースの選択と構築が適切に行われれば、RAGはビジネスにおける様々な場面で、より正確で有用な情報を提供できる可能性があります。
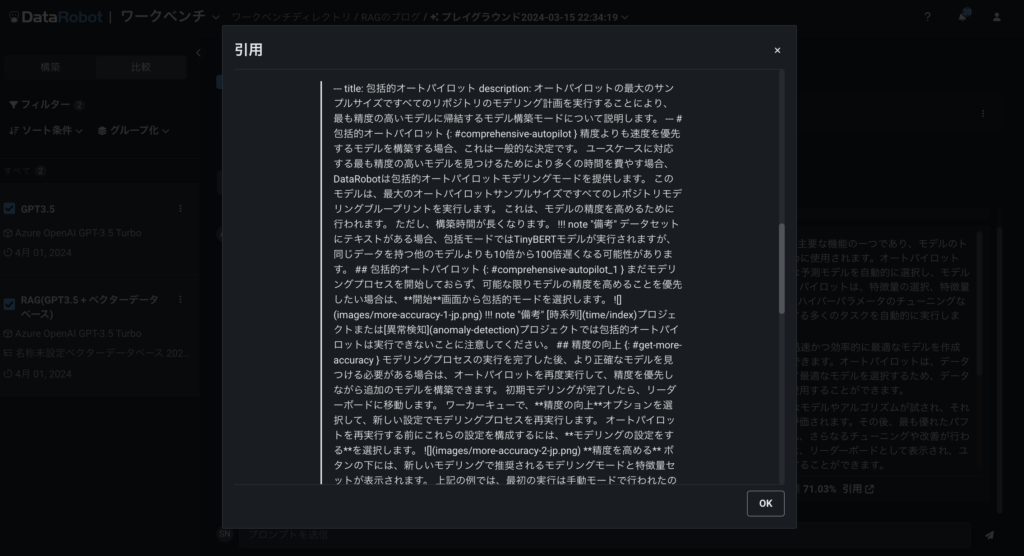
更に、RAGの場合は回答の生成に使った引用文を確認することができます。狙いたいドキュメントが正しく引用されているかなど、この画面を見ながらチェックします。
発展:RAG(Retrieval-Augumented Generation)のチューニングTips

最後に発展トピックスとしてRAGのチューニングのTipsについてご紹介します。RAGはデータの前処理やチャンキング戦略、プロンプトエンジニアリングと様々な改善ポイントがあるため、最初はどこから手をつけて良いのか分からないかもしれません。RAGは引用文を取得するまでの「検索パート」と引用文に含まれる情報から回答を生成する「生成パート」に分けることができます。大きな方針として、ドキュメントで狙いたい文章が引用文にない場合は、「生成パート」をいくら工夫しても精度を改善することは難しいので、まずは「検索パート」の工夫から考えてみるのが良いと思います。
「生成AI最前線:DataRobotを用いた実践RAG構築」Webinar無料視聴のご案内
本記事では、近年注目を集めているRetrieval-Augmented Generation(RAG)について、その基礎知識から実践的な活用方法までをDataRobotの生成AI機能にも触れながら包括的に解説いたしました。本記事が、RAGに関する理解を深め、皆様の生成AIプロジェクトの推進にお役立ていただければ幸いです。本記事と関連するウェビナー「生成AI最前線:DataRobotを用いた実践RAG構築」では、実際のデモンストレーションを交えながらRAGに関して解説しています。


