機械学習による生存予測
今回のトピックは機械学習による生存予測です。
生存分析
1990年代にアメリカの大学で勉強をしていたころ、70年代や80年代に製造された中古車にお世話になっていました。お手頃な価格で購入できる代わりに、よく故障したのを覚えています。学生時代に住んでいた町は車社会で、車が故障すると身動きを取ることができなくなって不便でした。
車に限らずコンピューターや製造ラインの機械などがいつ故障するか予測できたら、故障する前に手を打つことができて便利ですよね。機械がいつ故障するかを推定する手法はfailure time分析という名前でエンジニアリングの分野で活用されていますが、これは生存分析と呼ばれる、人が病気と診断された後どれくらい生存するかを分析する手法と同じです。ある事象がいつ起こるかを推定するという手法は様々な応用がありtime to event分析とも呼ばれますが、ここでは生存分析という名前を使いたいと思います。
生存分析の主な例としては次のようなものがあります。
- ヘルスケア(生存分析)
-
- 患者がいつ死亡するか
- 患者がいつ入院するか
- 患者がいつ病気にかかるか
- 製造(Failure Time 分析)
-
- 機械がいつ故障するか
- 材料がいつ耐えられなくなるか
- 商品がいつ使えなくなるか
- その他(Time to Event 分析)
-
- 顧客がいつ離脱するか
- 犯罪者がいつ再逮捕されるか
- 会社がいつ倒産するか
- いつ結婚するか、離婚するか、…
このように、あるイベントが起こるタイミングを推定できると、事前に手を打ったり情報を共有するなど、適切な準備が可能となります。
ヘルスケアの例ですと、患者がいつ死亡するかを推定することで、タイムリーな治療を提供してケアの質を向上できるようになります。患者がいつ入院するかを推定することで、薬やスタッフなどのリソースの適確な準備が可能となります。
製造業の例ですと、機械がいつ故障するかを推定することで、事前にメンテナンスが可能となり、故障した機械の修理や取り替えにかかる費用を削減できますし、機械の故障による生産ラインのストップによる損失も防ぐことができます。
他にも、顧客がいつ離脱するかでしたりアクティブユーザーがいつアクティブでなくなるかを推定するなど、生存分析の応用範囲は幅広いです。
ここでは、様々な課題で活用されている生存分析をどうやって機械学習で実行するかを紹介しますが、その前に、生存データの特徴についてお話しします。
打切りデータ
生存データの特徴のひとつとして、censoringというものがあります。これは、観測期間中にイベントが起こらなない場合や観測期間が終わる前に脱落者が出て観測不可能となる場合で、いつイベントが起こるかわからないという問題が生じます。
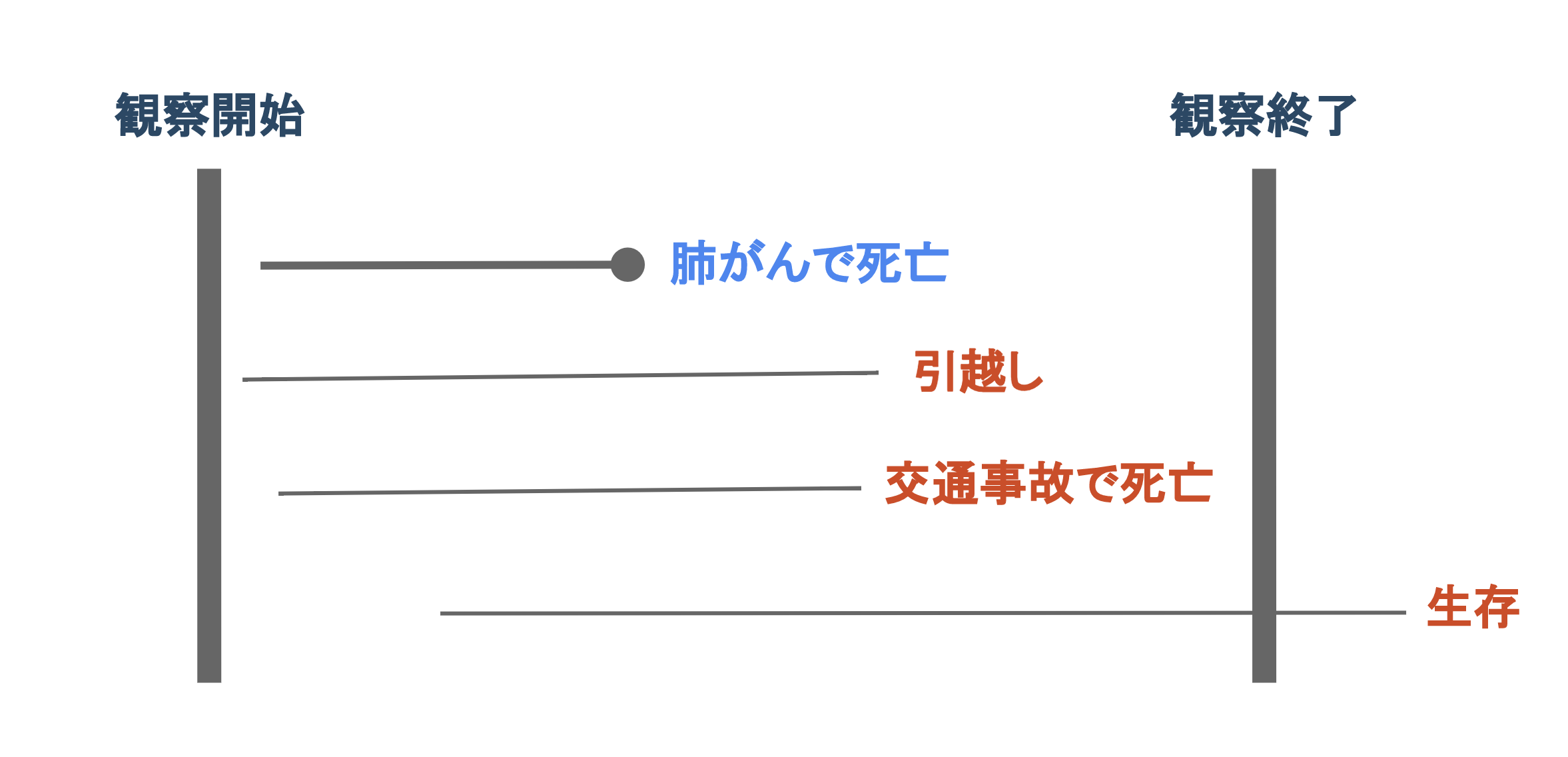
例えば肺がんの患者の生存時間を分析する際、上の図にあるように肺がんで死亡したケースは対象となるイベントです。しかし、観察が終了する前に引っ越してしまったり、交通事故など肺がん以外の理由で死亡してしまったり、観察期間内に死亡しないケースは打切りとなり、いつ対象となるイベントが起きるのかがわかりません。
下の表にある生存データの例で、具体的にみてみましょう。このデータに興味がある方はこちらをご参照ください:
Loprinzi CL. Laurie JA. Wieand HS. Krook JE. Novotny PJ. Kugler JW. Bartel J. Law M. Bateman M. Klatt NE. et al. Prospective evaluation of prognostic variables from patient-completed questionnaires. North Central Cancer Treatment Group. Journal of Clinical Oncology. 12(3):601-7, 1994.
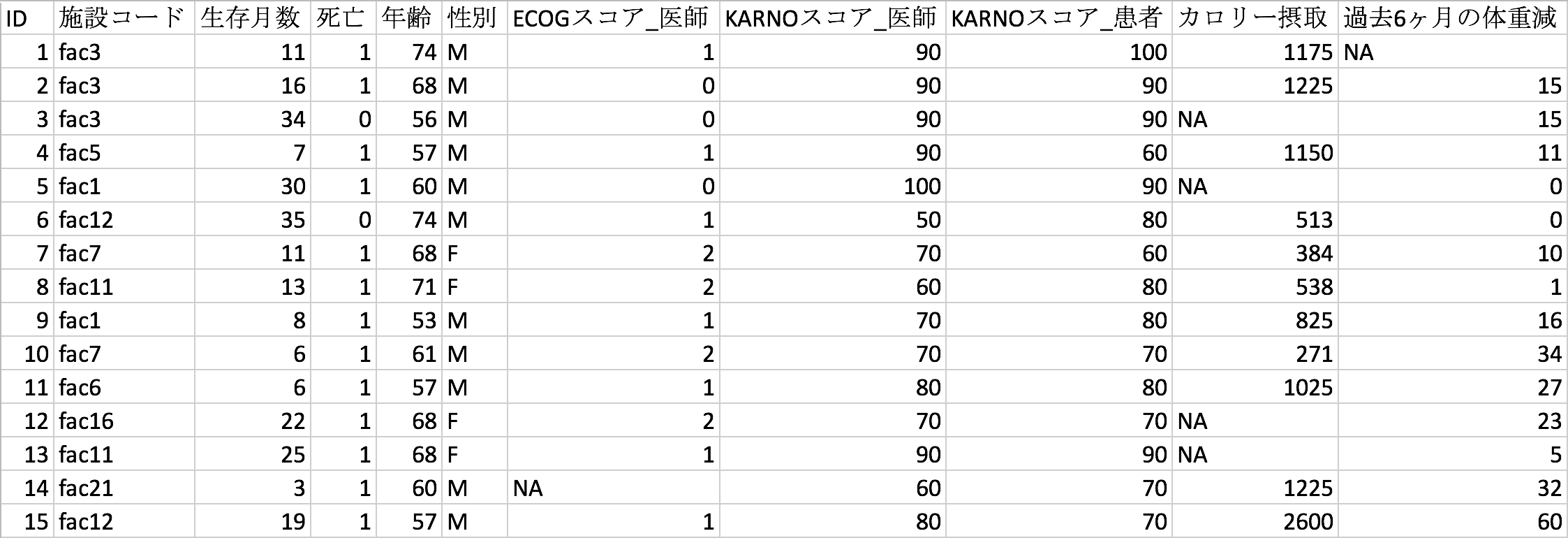
このデータでは、ひとつの行が一人の肺がん患者となっております。IDは患者の番号で、施設コードは患者が所属している施設の番号です。生存月数は、死亡(死亡=1)であれば、観測がはじまってから死亡するまでの期間です。例えば、ID 1の患者は観測開始から11ヶ月で死亡したので、生存時間が11ヶ月となります。ID 3の患者のように、観測期間中に死亡せず打ち切りになった場合は、生存時間が34ヶ月と記録されますが、これは、34ヶ月の時点で死亡していないことを意味していて、実際の生存時間は34ヶ月より長いということはわかるのですが、何ヶ月生きていたのかという正解はわからないことになります。
このように、打切りのケースは正しい生存時間がわからないため、生存時間を連続数値の回帰問題として機械学習で直接予測することはできません。
ひとつの解決法としては打切りのケースを取り除くことです。ここでの例ですと、肺がんで死亡した患者だけのデータを用いることで、打切りがなくなり、生存時間を直接予測したり、例えば3ヶ月以内に死亡するかどうかの二値分類をすることができるようになります。
ただ、現状は、打切りのデータがたくさんあり取り除くことができなかったり、死亡した患者だけではなく、患者全体の分析をすることが目的であったりして、打切りデータがある状態で生存時間を推定する必要があるといったケースがあります。
そこで登場するふたつ目の解決策が生存分析です。
生存分析の手法
それでは、生存分析ではどのように生存時間を推定するのでしょう。
最もシンプルな生存分析手法にKaplan-Meier法というものがあります。Kaplan-Meier法では、ある時点での生存者数をその時点での対象者数で割ることによって、その時点の生存確率を求めます:
P_i = (S – D – C) / (S – C)
S = その時点まで生存した人数
D = その時点で死亡した人数
C = その時点で打切りになった人数
ここでカギとなるのが、この時点より前に打切りになったケースはこの時点より前に死亡したケースと同様に、対象者に含まれませんが、この時点でまだ打ち切りになっていないケースは対象者に含まれるということです。このようにして打切りケースに対応します。そして、ある時点までの生存確率を、その時点での生存確率とそれより前の確率の掛け算で求めることによって、時間とともにどう生存確率が変わるかを生存曲線として表します。
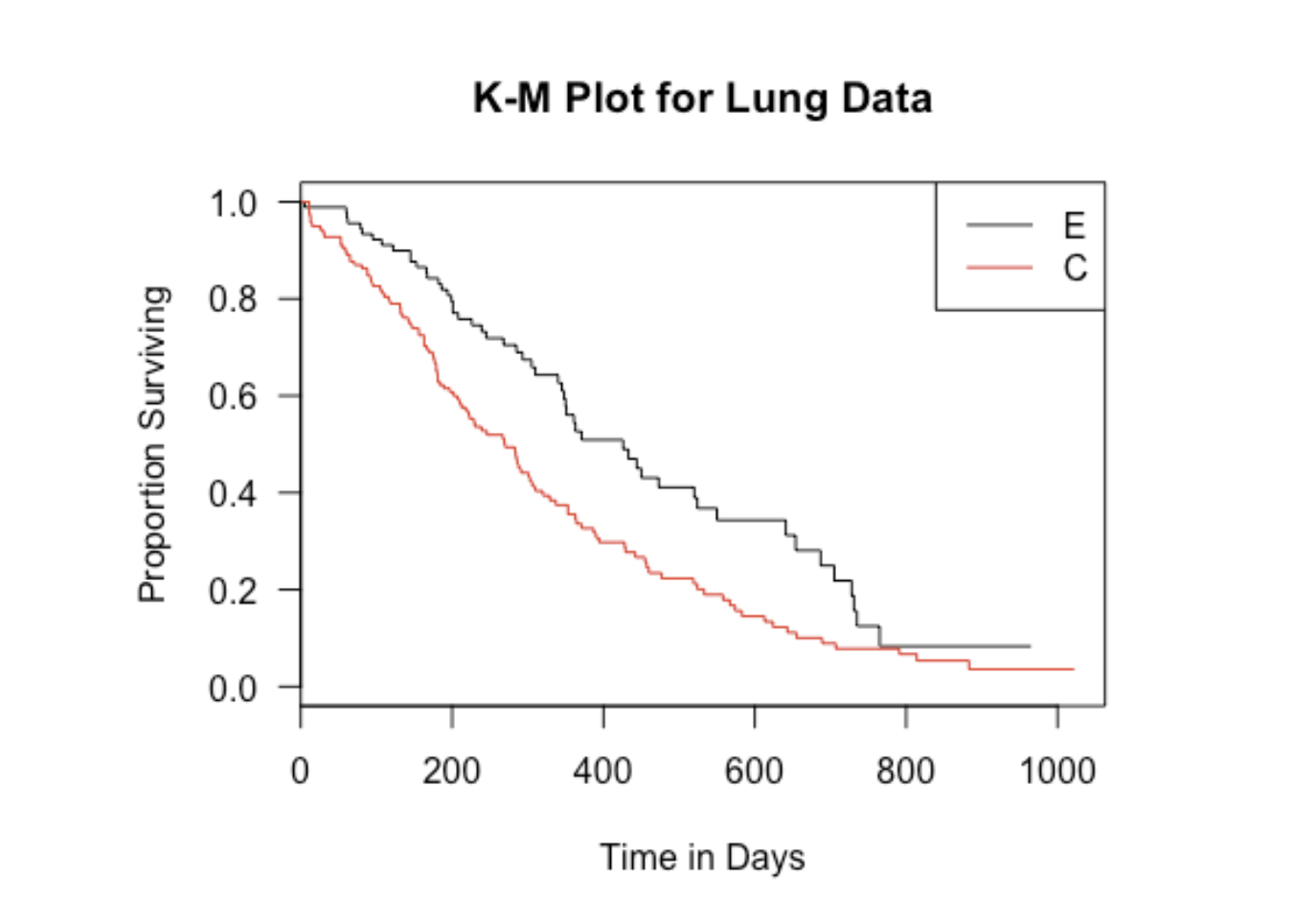
Kaplan-Meier法の活用の仕方として、2つ以上のグループの生存曲線の比較があります。例えば、下の図で、今までの薬がCの赤い生存曲線で、新しく開発された薬がEの黒い生存曲線とします。横軸が日数で、縦軸が生存割合となります。この赤と黒の二つの生存日数曲線をを比べることによって、新しい薬の効果を調べることができます。この例ですと、黒い曲線で表されている新しい薬の方がより長く生存している人の割合が増えているのがわかります。
Kaplan-Meier法はシンプルで便利ですが、複数の要因が生存に及ぼす影響を見ることができません。このような場合に活用できる手法にCox回帰というものがあります。これは、時間的要素も考慮して、複数の要因のイベント有無への影響度合いを分析する方法です。ある時間でのハザード率λを、その時間のベースラインハザード率λ0とリスク要因を用いて求めるというものになります:
λ(t|x1, · · · , xn) = λ0(t) exp(β1×1 + · · · + βnxn)
ハザードとは、その時点まで生存していたという条件の下で、次の時点で死亡する確率です。ベースラインハザードは、Kaplan-Meier法と考えていただくことができ、そうすることにより、打切りケースに対応することができます。このように、打切りデータを含む場合は、ロジスティック回帰では扱えませんが、Cox回帰では扱えます。
より最近の手法ですと、Random Survival Forestsという機械学習を生存分析に応用したものや、Deep Learningを生存分析に応用するというものがあります。最新の機械学習アルゴリズムを使用することで生存分析の精度を上げることができます。
DataRobotには、今現在、Kaplan-MeierやCox回帰またRandom Survival Forestsといった生存分析の手法は入っていませんが、データをperson-periodフォーマットで準備することによって、汎用的機械学習で生存予測が可能になります。Person-periodデータを使用すれば、DataRobotで準備しております様々な機械学習のアルゴリズムで生存予測モデルを生成できます。
Person-Periodデータ
一般的によくある生存分析データは、person-levelと呼ばれる形式で、ひとつの行が一人の患者であったりひとつの機械で、その患者もしくは機械の生存期間にくわえて、イベントが起きたかどうかのフラグと様々な属性や行動情報が記録されています。上の表の生存データがperson-levelの例となりますが、このperson-levelのデータをperson-period形式に変換すると、下のデーブルのようなものになります。
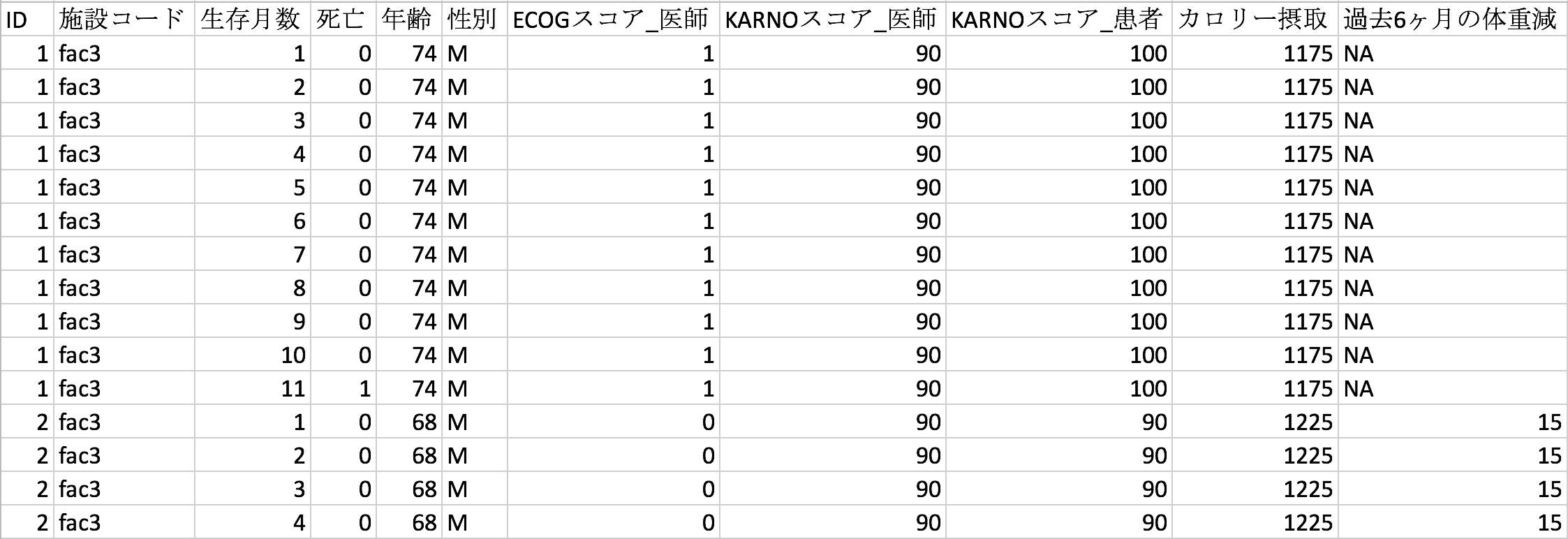
Person-periodデータを作成するには、ひとつの行をある人のある期間にして、その期間にイベントが起こったかどうかのフラグを記録します。例えば11ヶ月で死亡した患者ID 1の場合、person-levelデータでは1行でしたが、person-periodデータでは11行となり、11期間のそれぞれで死亡したかが記録されています。患者ID 1のケースでは、生存月数が1から11になり、11ヶ月目に死亡を意味する1がつき、それ以前の期間では死亡ではない0がつきます。
このように、データを期間に分割することで、機械学習を使って各期間で死亡するかであったり故障するかを学習し、未来の期間について予測することができます。
DataRobotによる生存予測
打切りがなければ、person-levelのデータの生存時間を予測する機械学習の回帰問題としてDataRobotで予測モデルを生成できますが、今回の例のように、打切りがある場合がほとんどです。打ち切りがある場合は、生存時間を直接予測することはできないので、person-periodのフォーマットにデータを変換して、DataRobotで予測モデルを生成します。
今回の例ですと、person-levelデータの死亡カラムをターゲットに設定して、モデル生成を開始します。ここで2つ注意点があります。
- ひとつは時間の情報が何らかの形で特徴量セットに含まれているということです。ここでは、生存月数です。最終的に死亡した患者の場合、その患者の最後の期間で死亡フラグが死亡を表す1となり、それ以前の期間は0となります。
- もうひとつ気をつけなくてはならない点は、データの分割です。機械学習のモデルを生成する時、モデル学習用データとモデル検定用データを分ける必要があります。今回のようにperson-periodのデータでモデルを生成する場合、同じ患者の情報が複数の行に出現することになります。患者ID 1の場合、観測開始から死亡するまで11ヶ月で、それぞれの月で死亡するかを予測しますので、この患者のデータは1行となります。このようなデータを学習用と検定用に分割する時、同じ患者のデータの一部が学習に使われて残りが検定に使われるということ防ぐ必要があります。例えば、患者ID 1の4ヶ月から11ヶ月までのデータを学習して生成されたモデルでこの患者の1ヶ月から3ヶ月までのデータで予測をしてモデル検証をするというのは理想的ではありません。そこで、DataRobotの開始ボタンを押す前に、高度なチューニングの画面で、IDカラムの情報でグループ化したデータの分割方法を実行します。そうすることで、同じ患者のデータは同じ分割に入るようになります。
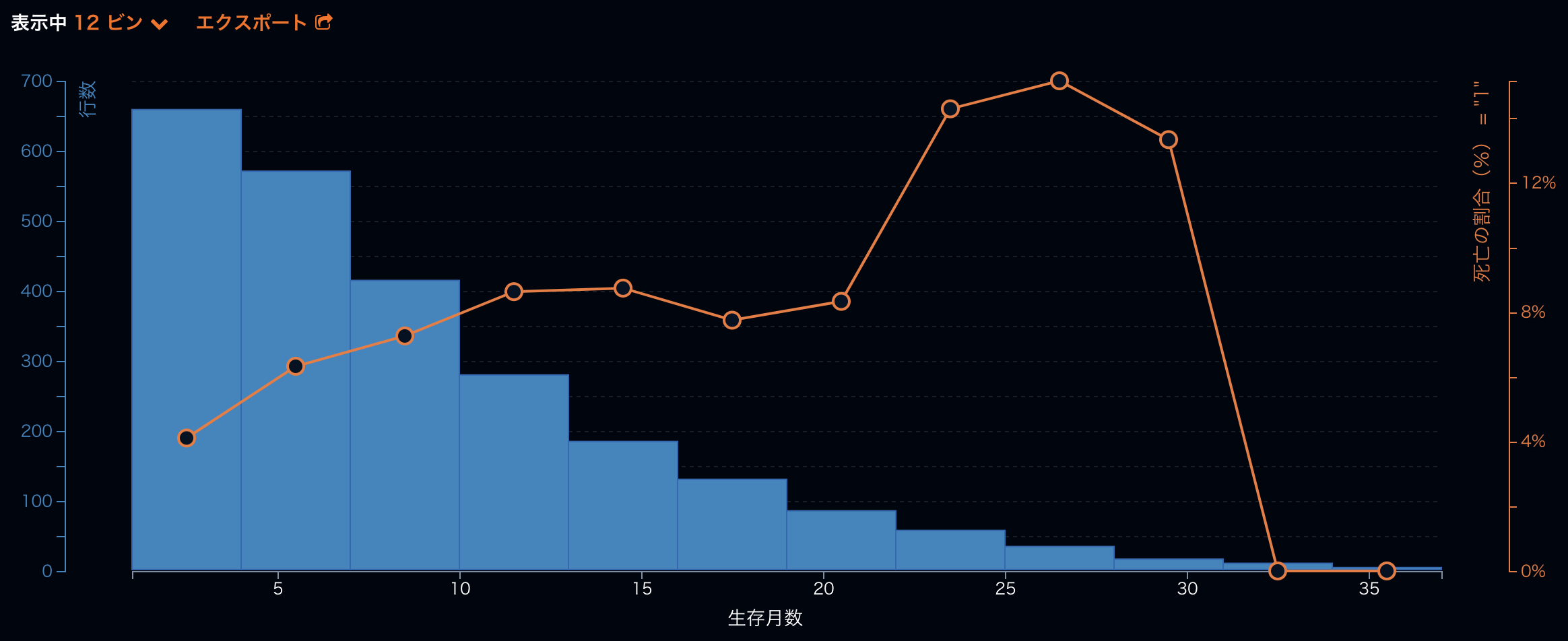
DataRobotで予測モデルを生成すると、各患者が各期間で死亡する確率だけではなく、データやモデルを解釈する上で役立つ情報も得ることができます。例えば、下のグラフでは、生存月数と死亡の割合の関係を理解することができます。横軸が生存月数で、この例ですと、生存月数を小さいものから大きいものに並べて、12のビンに分けたものとなっています。ビンとは入れ物です。左の縦軸は各生存月数のビンに入るデータの行数です。右の縦軸は各ビンでの死亡の割合です。このグラフから、生存月数が増えると死亡の割合が大きくなる傾向にあるとわかります。25ヶ月あたりで死亡の割合が大きくなります。
このようにDataRobotでは生存月数などの各特徴量と過去に死亡したかというターゲットの関係を可視化して、Kaplan-Meier法と同じような情報を得ることができます。DataRobotで計算された死亡率を1から引いて生存率をだし、生存率を掛けることで、Kaplan-Meier法と同じ生存曲線を描くことができます。
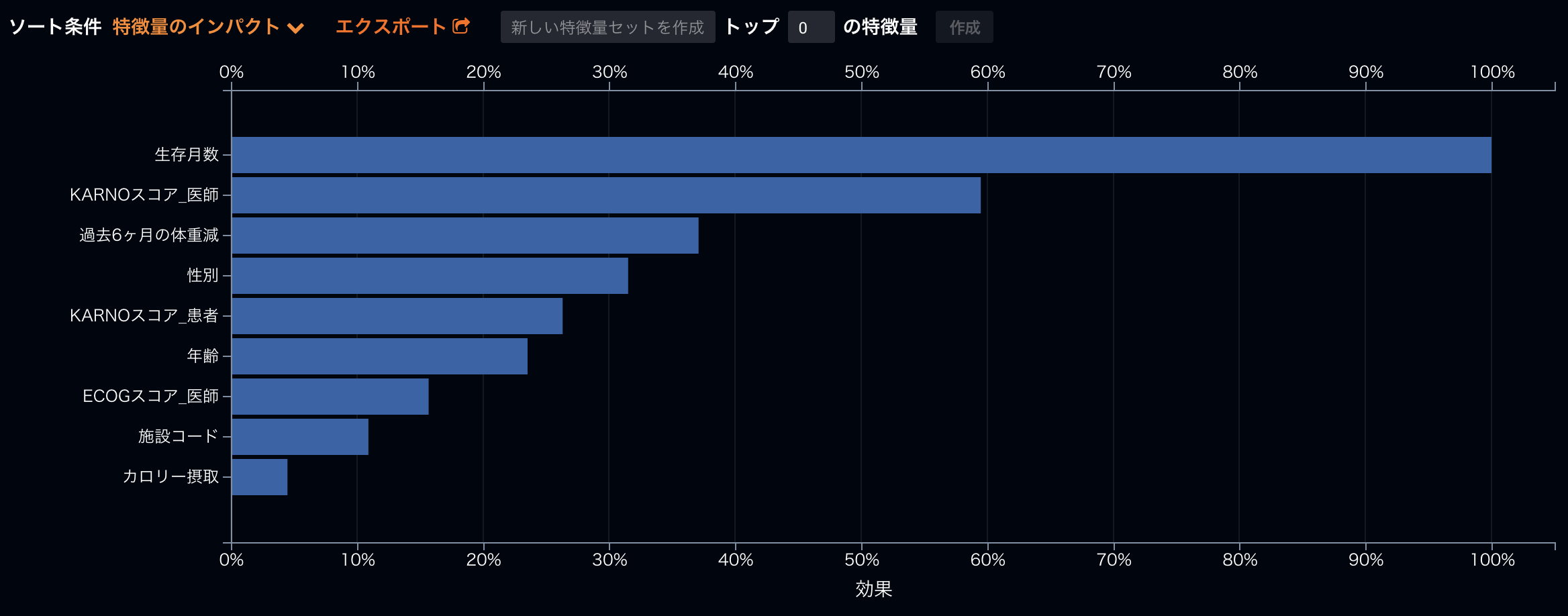
また、Cox回帰のように、DataRobotで生成されたひとつひとつの予測モデルで、各要因が死亡に及ぼす影響を理解することができます。例えば特徴量のインパクトという機能から、下のグラフのように、あるアンサンブルモデルの予測の精度にどの特徴量が効いているかを見ることができます。いちばんインパクトのある特徴量である生存月数が100%の場合、その他の特徴量が相対的にどれくらいの影響力かを示しています。このモデルに2番目に効いている特徴量は医師のKARNOスコアだということがわかります。これは、医師によるKarnofskyパフォーマンス点数で、0=poor 100=goodとなります。
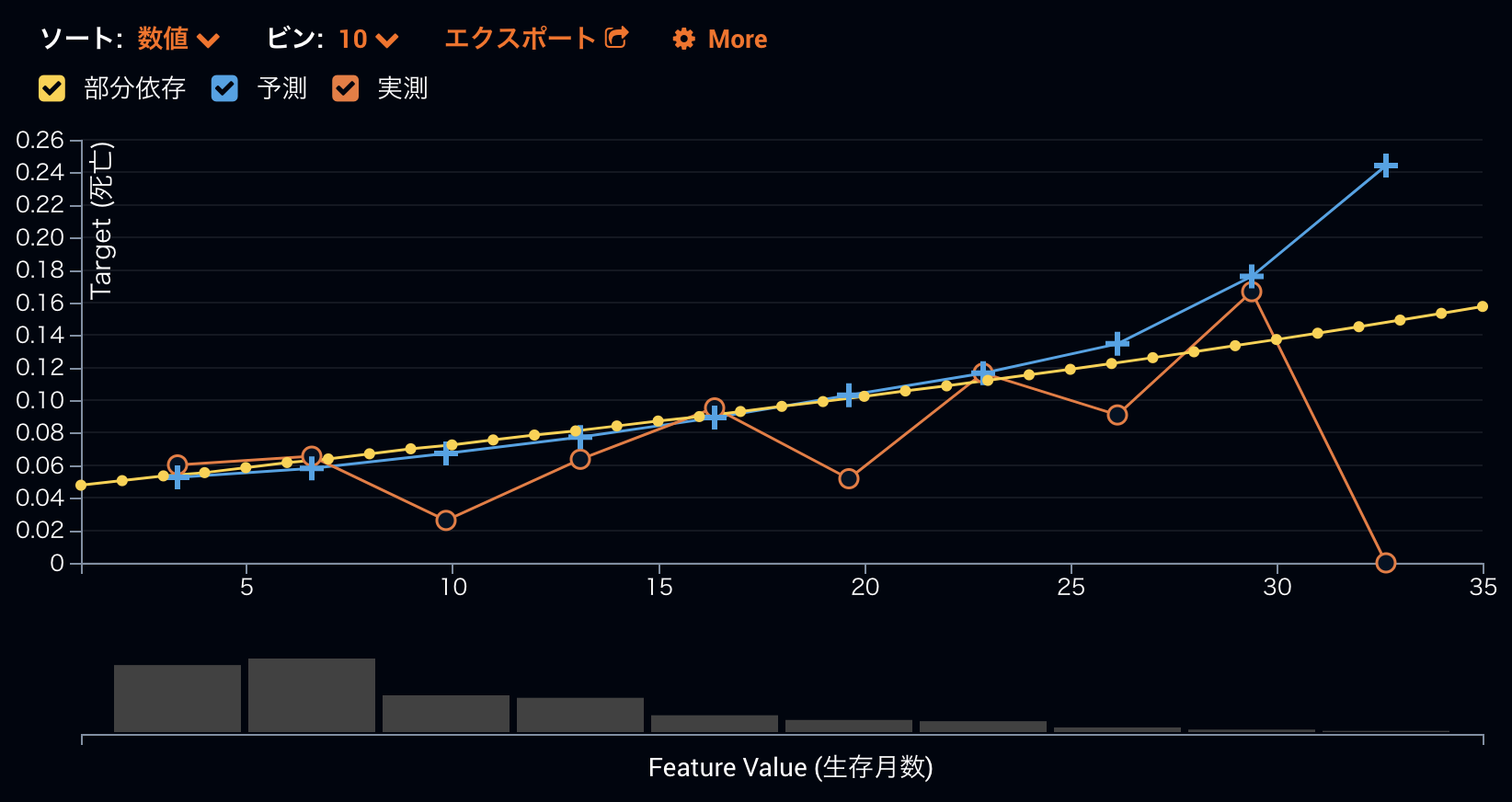
DataRobotでは、モデルX-Rayという機能を使用して、各特徴量と過去の結果の関係だけではなく、各特徴量と予測の関係も見ることができます。例えば、生存月数が死亡する予測確率とどう関係しているかを下のグラフから理解することができます。青い線がモデルの予測値でオレンジの線が実測値となります。黄色い線は部分依存というもので、他の特徴量をそのままにして、生存月数のみの値を変えた時に死亡予測値がどのように変わるかを計算したものとなります。黄色い線を見ることによって、この特徴量単独での死亡予測へのインパクトを理解することができます。
このように、DataRobotの特徴量のインパクトやモデルX-Rayという機能を使用して、時間ごとの予測死亡割合だけではなく、要因分析も可能です。例えば、医師のKARNOスコアが死亡するかに重要だという仮説があるのであれば、仮説検証ができますし、もしそういった仮説がなければ、医師のKARNOスコアが死亡するかに重要だという分析結果は新しい気づきになるかもしれません。これは、選択されたモデルに対して、患者全体の死亡確率を考慮した時にどの特徴量が重要かという分析になります。
機械学習モデルを生成したら、新しい患者が死亡する予測を出すことができます。例えば、3人の患者に対して、25ヶ月先まで5ヶ月ごとに死亡する確率を予測したのが下の表です。これらのDataRobotで予測された死亡確率(Prediction)を1から引いて生存確率を計算し、前の期間の生存確率と掛けることで、ID 1000とID 3000とID 5000の3人の患者ひとりひとりの生存曲線を理解することができます。
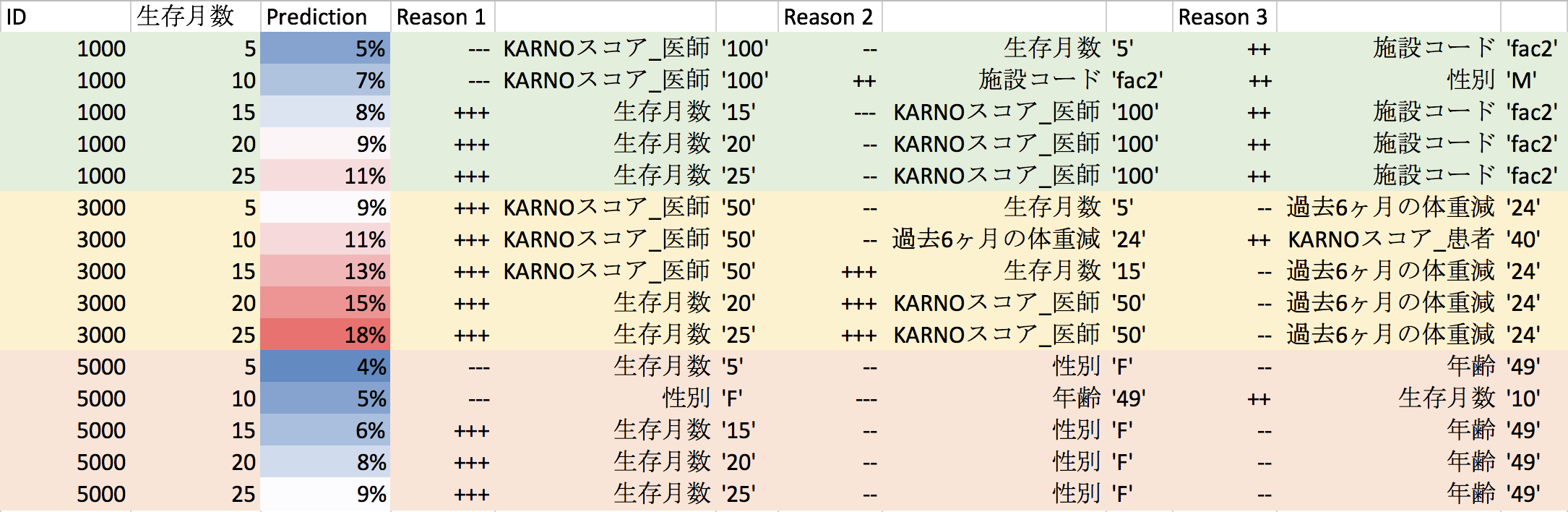
ID1000の方は5ヶ月では死亡確率が5%と予測され、25ヶ月では11%と予測されています。DataRobotでは、予測値だけではなくどうしてそういう予測値になったのかという理由も最大10個まで計算してくれます。ID1000の方の場合、医師のKARNOスコアが100で高く生存月数が5で低いので、5ヶ月の予想死亡確率は5%と低く出ていると説明してくれています。ID3000の方の25ヶ月の予想死亡確率は18%と高く、その理由は生存月数が25で高く、医師のKARNOスコアが50で低いからとなっています。ID5000の方の予想死亡確率が全体的に低いのは性別が女性で比較的に若いからということがわかります。
予測の理由は、特徴量のインパクトやModel X-Rayのように患者全体の死亡確率の要因を分析するのではなく、ある患者のある期間の死亡確率の理由をひとつひとつ分析します。DataRobotでは、全体的に重要な特徴量と、ひとつひとつのケースに重要な特徴量の両方を分析してくれます。ある患者の死や機械の故障に全体的にどのような特徴量が重要かという理解をベースに解決策をプランすることができます。また、一人の患者のある期間の死亡確率やひとつの機械のある期間の故障確率にどのような特徴量が重要かを理解することによって、より状況に合ったアクションをとることができるようになります。
このようにDataRobotで機械学習モデルを生成して、予測にフォーカスしたモデルX-Rayや予測の理由などを見ることによって、Kaplan-Meier曲線やCox回帰では得られなかったインサイトを得ることができます。また、最新のアルゴリズムも含め、様々な機械学習の手法を使うことにより、生存予測の精度をより高くすることができます。
まとめ
今回は機械学習による生存予測についてご紹介いたしました。データに打切りがない場合は機械学習の回帰問題として直接生存期間を予測することができますが、打切りがある場合は、person-periodのフォーマットにデータを変換して、それぞれの期間で死亡する確率を予測していただく形になります。そうすることで、ヘルスケアや生命保険での生存予測、製造業での予知保全、またチャーン分析など、ある事象がいつ起こるかという様々なケースでより精度の良い生存予測をすることが可能となります。機会がありましたらお試しください。
DataRobotは、ビジネスへの影響を最大化し、リスクを最小限に抑えるAIを提供しています。当社のAIアプリケーションとプラットフォームは、コアビジネスプロセスに統合され、チームがAIを開発、提供、管理することを支援します。DataRobotは、実務担当者が予測および生成AIを提供し、リーダーがAI資産を保護することを可能にします。世界中の組織が、現在そして将来にわたり、ビジネスに役立つAIを提供するDataRobotに信頼を寄せています。詳細については、当社のウェブサイトをご覧ください。LinkedInのフォローもお待ちしています。
-
データとの対話:AIエージェントによる迅速かつ説明可能な回答
2025年4月16日| 推定読書時間 3 分 -
DataRobot Customer向けニュース(March)
2025年3月26日| 推定読書時間 1 分 -
DataRobotのPlaygroundにLLMをホスティングする方法
2025年3月11日| 推定読書時間 2 分
最近のブログ記事

