DataRobotのPlaygroundにLLMをホスティングする方法
本ブログはQiitaに掲載した記事「DataRobotのPlaygroundにLLMをホスティングしてみた」の転載となります。

1. はじめに
こんにちは、DataRobotデータサイエンティストの長野です。普段はDataRobotでデータサイエンティストとして製造業・ヘルスケア業界のお客様を担当しています。技術面では生成AIプロジェクトのリードを担当しています。本記事では、DataRobotのBYOLLM(Bring Your Own LLM)と呼ばれる仕組みを用いて、Hugging Face Hubから取得したLLMをDataRobot環境にホスティングする方法をご紹介します。
なお、本ブログはウェビナー「DataRobot × NVIDIAで加速する予測AIと生成AI~RAPIDSからNeMo Guardrailsまで」で解説した一部の内容を詳細化した記事となります。 是非アーカイブも合わせてご覧いただければと考えます。
2. LLMホスティングとは
LLMホスティングとは、外部のAPIに依存せず、LLMを自前の環境(DataRobot等)にデプロイして運用する手法です。関連した用語として、ローカルLLMと呼ばれる手法は自社のオンプレミス環境にLLMをホスティングすることを指します。近年、DeepSeekやTinySwallow1.5B等、オープンソースのLLMで高精度なモデルも出てきているので生成AIプロジェクトの一つの選択肢としてチェックしていただければと考えます。私が担当している製造業やヘルスケア業界ではセキュリティ要件の厳しいケースが多く、今後の生成AIプロジェクトにおける重要な選択肢の一つになってくると考えます。
LLMホスティングのメリットとデメリットは以下の通りです。
メリット
- コスト削減:API利用料が不要となるため、リクエストが多いユースケースでコスト削減につながる。
- セキュリティ向上:APIを経由せずに利用が可能。ローカルLLMの場合は閉域網での利用が可能。
- 柔軟な運用:自社環境に合わせたカスタマイズやチューニングが自由に行える。
- 運用監視の容易さ:外部ベンダーによるLLMの更新や仕様変更の影響を受けない。
デメリット
- 初期設定の複雑さ:環境構築やモデルの最適化に手間がかかる。
- 運用負荷:ハードウェア・インフラ管理に運用リソースが必要。
- パフォーマンスの差:商用モデルと比較し、選択したGPUサイズによっては精度や応答速度で劣る場合がある。
- コンプライアンスの懸念:コンプライアンステスト等が不十分な可能性がある。
DataRobot上でLLMをホスティングする際は、GPU環境を扱えるためデメリットである初期設定の複雑さや、運用負荷を軽減できる点がポイントです。今回は、DataRobotのPlayGround環境上で任意のLLMを実行できる仕組みである「BYOLLM(Bring Your Own LLM)」を利用して、具体的なホスティング手順をご紹介します。
3. LLMホスティング実行手順
以下は、Hugging Faceから取得したcyberagent/DeepSeek-R1-Distill-Qwen-14B-Japaneseを用いて、DataRobot上でLLMをホスティングする手順です。詳細は「ドキュメント:Hugging FaceハブからのLLMのデプロイ」をご参照ください。
最初にDataRobotのNextGenの画面からモデルワークショップ→モデルの追加を押します。
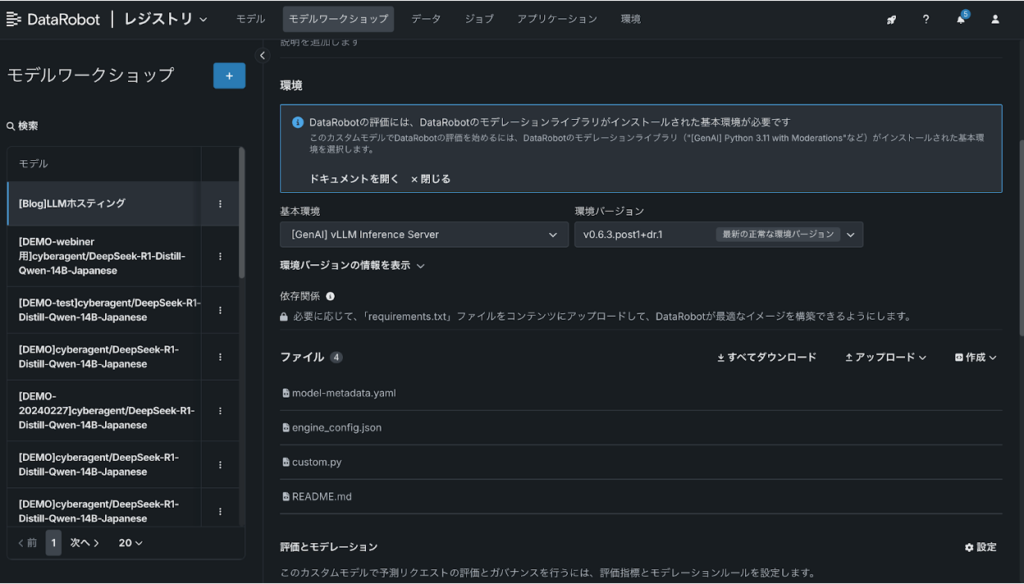
基本環境として[GenAI vLLM Inference Server]を選択します。こちらの基本環境を用いることで、複雑な環境構築なしですぐにHuggingFace HubからLLMをホスティングすることが可能です。このように基本環境はプリセットのものをお使いいただくことをおすすめしますが、ご自身で自由にカスタマイズした環境を構築することも可能です。次にGitHubリポジトリから関連するアセットをダウンロードしていただきます。リポジトリ内のgpu_vllm_textgenフォルダ内の以下の4つのファイルを下記のようにドラッグ&ドロップします。
- runtime.yaml
- custom.py
- engine_config.json
- requirements.txt
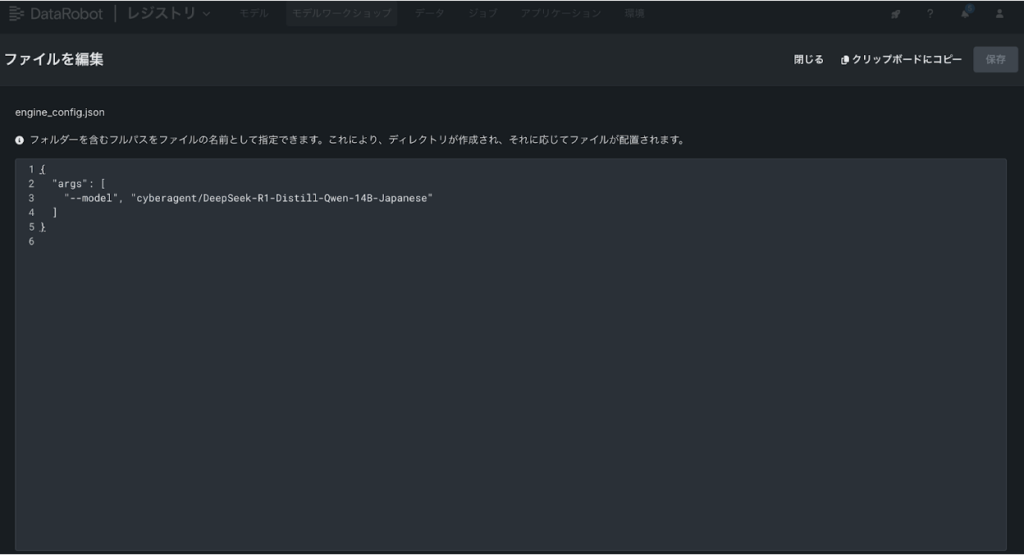
次にengine_config.jsonがデフォルトだとmeta-llama/Llama-3.1-8B-Instructをホスティングする仕様になっているので、今回はcyberagent/DeepSeek-R1-Distill-Qwen-14B-Japaneseに書き換えてください。最初は難しそうに見えるかもしれませんが、モデル毎に変更が必要なのは基本的にengine_config.jsonと後述するGPU環境のみです。
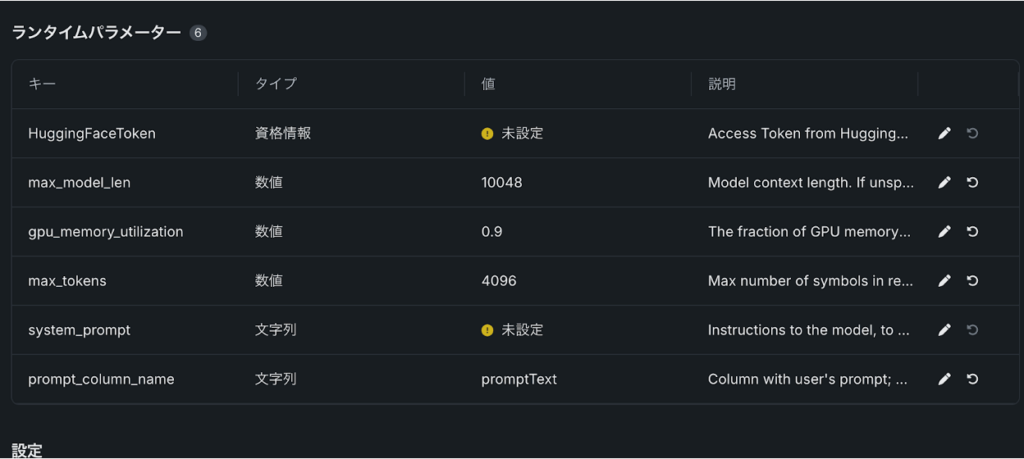
その後にHuggingFaceTokenとシステムプロンプトの設定をします。HuggingFaceTokenは、Hugging Faceのアカウントの設定画面から取得可能です。初回利用時は、事前に用意しておくことをおすすめします。システムプロンプトの設定は任意のオプションです。
最後にリソースバンドルを設定します。どのリソースを選ぶかの参考としてドキュメントに記載の計算式をご活用ください。ドキュメントに記載のLlama−3.1-8bの場合はLバンドル、今回のケースではP=14, Q=16で計算するとM≒33.6GBなのでVRAMが48GBのXLサイズを選定しました。ブログ執筆時点ではVRAM 384GB(5XL)まであるので、計算上は160Bクラスのモデルもデプロイ可能です(参考値のため実際にはテストをする必要があります)。
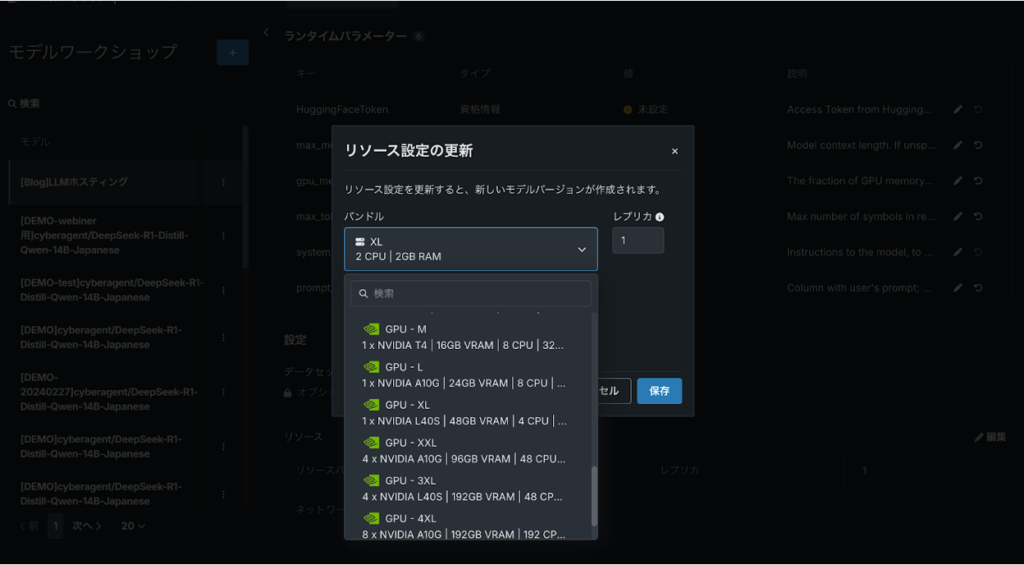
モデルの登録とデプロイをしていただき、手順に問題がなければLLMのホスティングが完了です。コンソールの画面から普段お使いいただいているデプロイモデルと同様に、LLMの運用監視やAPI連携が可能です。
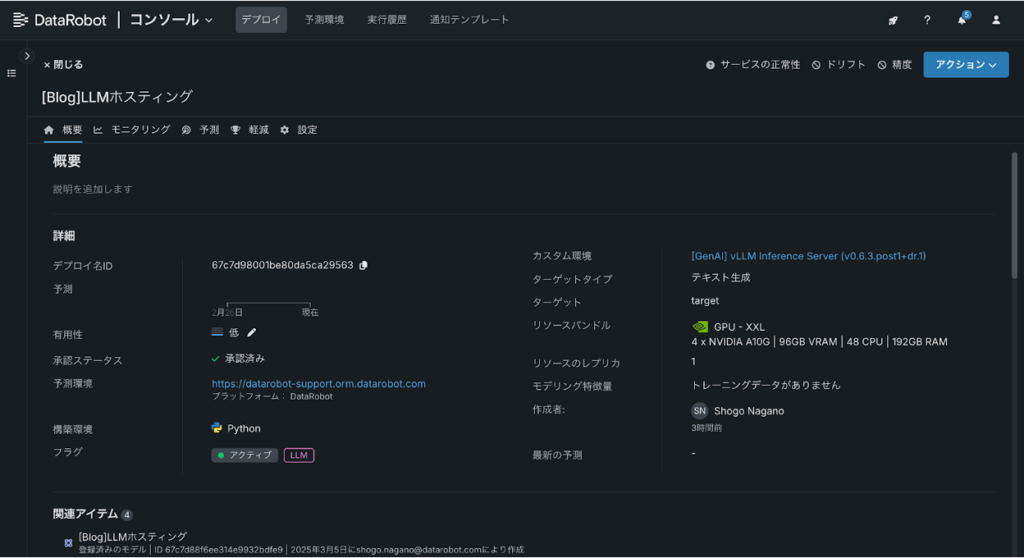
続いて、BYOLLMの仕組みを用いてPlayGround上でLLMを検証します。下記の通り、「デプロイ済みLLMを追加」をクリックしてください。
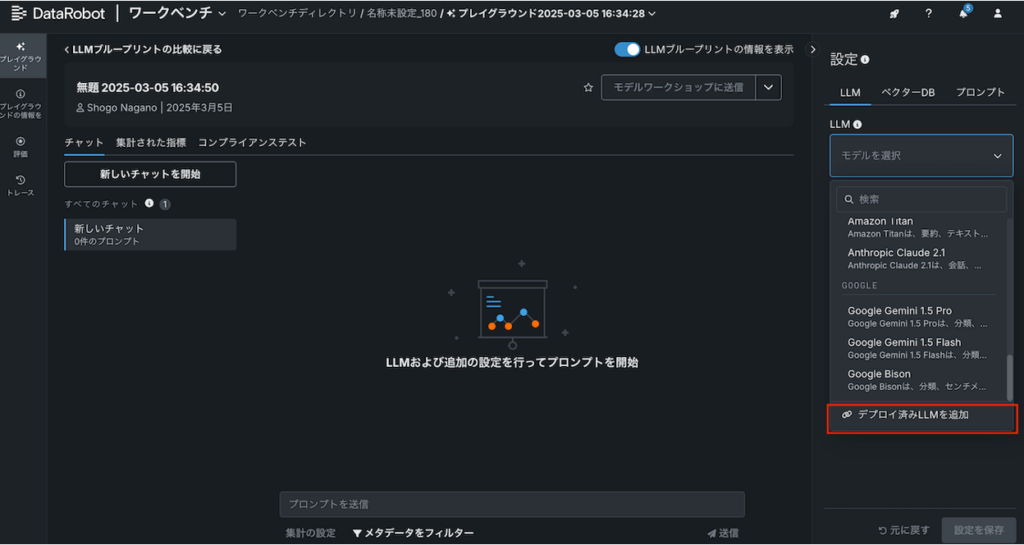
下記のポップアップが表示されるのでデプロイ名から先ほどデプロイしたLLMを選定してください。プロンプト列はpromptText、ターゲット列はLLMホスティングの設定で決めたターゲット名を入力してください(今回のケースではtarget)。
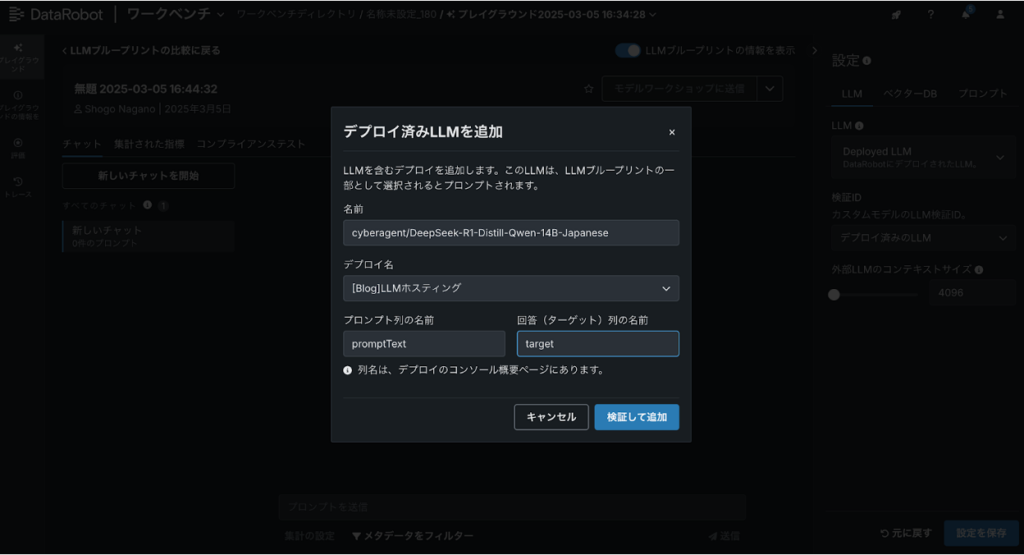
成功するとLLMの中にDeployed LLMという項目が表示されるので、設定すると下記の通りホスティングされたLLMを使うことができます。インターフェース上は分かりにくいですが、GPT系のLLM等とは違い、DataRobotのGPU環境上で構築されたLLMと対話しています。
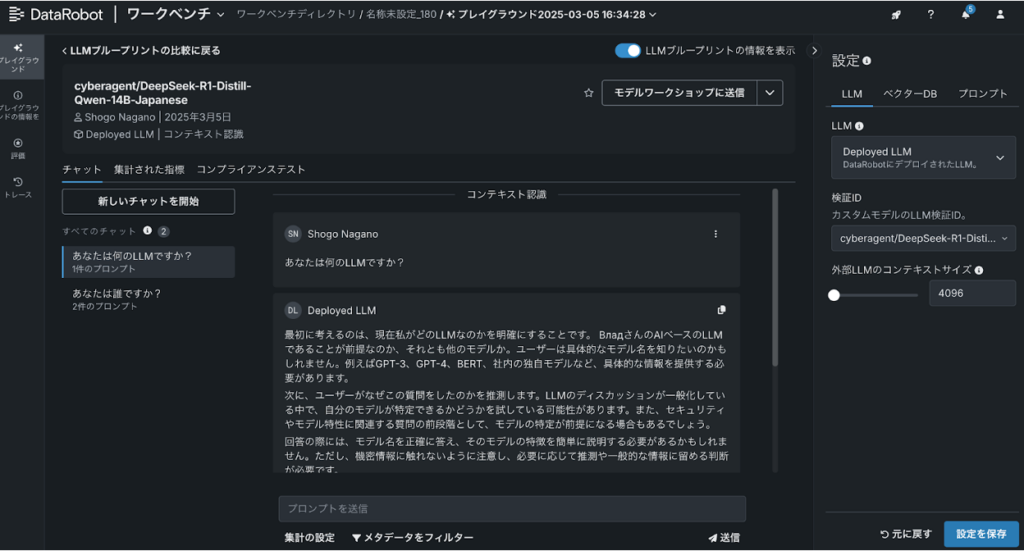
4. LLMホスティングの次のステップ
ホスティングしたLLMは、DataRobotにプリインストールされている商用LLMと同様の操作感で手軽に検証や評価が可能です。現時点で、オープンソースLLMは商用LLMに精度や性能面で完全には及ばないものの、今後の精度改善に向けて次のようなアプローチを検討できます。
- システムプロンプトの最適化
- RAGの活用
- 自社データを用いたファインチューニング
これらの技術要素の組み合わせや問題設定次第では、LLMホスティングが最適となるケースもあります。DataRobotではRAGの構築やシステムプロンプトはもちろん、GPU環境を用いたファインチューニングも可能なため、是非検討いただければと思います。
5. まとめ
本記事では、DataRobotのBYOLLMを活用し、Hugging Face Hubで公開されているLLMをDataRobot環境にホスティングする手順を解説しました。オープンソースLLMは商用LLMと比較すると現時点で精度や性能面では完全に同等とは言えませんが、コスト削減やセキュリティ向上、自社環境への柔軟な適応といった面で優位なケースも多くあります。さらに、システムプロンプトやRAG、自社データによるファインチューニングを活用すれば、実務で十分に使えるレベルまで性能を引き上げられる可能性があります。
DataRobotでは、オープンソースLLMのホスティングと商用LLMの利用、両アプローチを簡単に比較検証できます。今回の内容が、皆様の生成AIプロジェクトの新たな選択肢としてお役に立てば幸いです。

DataRobotにて、製造業およびヘルスケア業界のお客様を中心に、AIおよびデータ活用の推進を担当。日本市場におけるDataRobot生成AI機能の活用促進とカスタマーフェイシングをリード。前職では、自動車業界のDX推進組織にてデータサイエンティストとして、モデリングやコンサルティングから社内教育、分析ツールの開発まで幅広く担当。博士(工学)。
-
DataRobot Customer向けニュース(March)
2025年3月26日| 推定読書時間 1 分 -
DataRobot CodeSpaceでLLMを活用した名寄せ処理の実行
2025年3月11日| 推定読書時間 4 分 -
AIエージェント:夢の実現か、それとも幻影か? 私たちの生活とビジネスの未来
2025年2月21日| 推定読書時間 3 分
最近のブログ記事


