機械学習を用いた要因分析 – 理論編 Part 1
こんにちは、DataRobotのデータサイエンティスト伊地知晋平です。
今回、2018年7月に開催しましたワークショップ「機械学習を使った要因分析」でご紹介させていただいた内容を元に、山本祐也さんと分担して3本のブログを書きました。今週から3週間に渡って、「理論編 Part 1 (8/13公開)」「理論編 Part 2 (8/20公開)」「実践編 (8/27公開)」をアップしてまいりますのでお楽しみいただければ幸いです。
上記リンク先には、ワークショップで使用したプレゼン資料やハンズアウトで使ったサンプルデータがアップされています。DataRobotユーザーの方はぜひご活用ください。
※理論はあと回しでいいからまずはDataRobotで要因分析をどうやるのか知りたい、という方は、山本さんのブログ「機械学習を用いた要因分析 – 実践編」(8/27公開)を参照ください!
要因分析とは何か? 要因が分かると何が嬉しいのか?
「機械学習を使った要因分析ワークショップ」では、何らかの結果をもたらしている原因(要因)を特定する作業を要因分析と定義しました。では私達はそもそも何のために要因分析をやるのでしょうか。
小社データサイエンティストがお客様とお話しすると、「機械学習で要因分析をしたい」とのご相談をいただく機会が実はかなり多いのですが、その理由をお尋ねすると「要因を特定して、何らかの施策を打ちたいから」あるいは、「ある施策が効果的なのかどうかを検証したいから」とのご回答をいただきます。例えば、以下のようなご要望のイメージです。
- 工程で収集しているデータを分析して、歩留まりのばらつきに影響を与えている要因を特定し、その要因をコントロールして歩留まりを安定させたい
- コマーシャル系データを分析して、過去に行ったマーケティング施策が本当に売り上げ増加に繋がっているかどうかを検証したい
これらは機械学習が得意とする「予測タスク」とは目的が違っていますが、中には、「モデルの予測精度はそこそこでも良いので、要因を素早く効率的に突き止めたい」とまでおっしゃるお客様もいらっしゃいます。すなわち、「予測して当てる」よりも「特定された要因に対して何らかのアクションをとって、より好ましい結果を得たい」から要因分析が行われます。
この、要因に対して何らかのアクションをとって、がポイントで、要因分析が目指すゴールは、「何らかのアクションが取れる要因の特定」になります。(何らかのアクションをとる、と同じ意味で統計的因果推論や疫学の分野で使われる用語「介入(Do)」を以降この稿では用います)
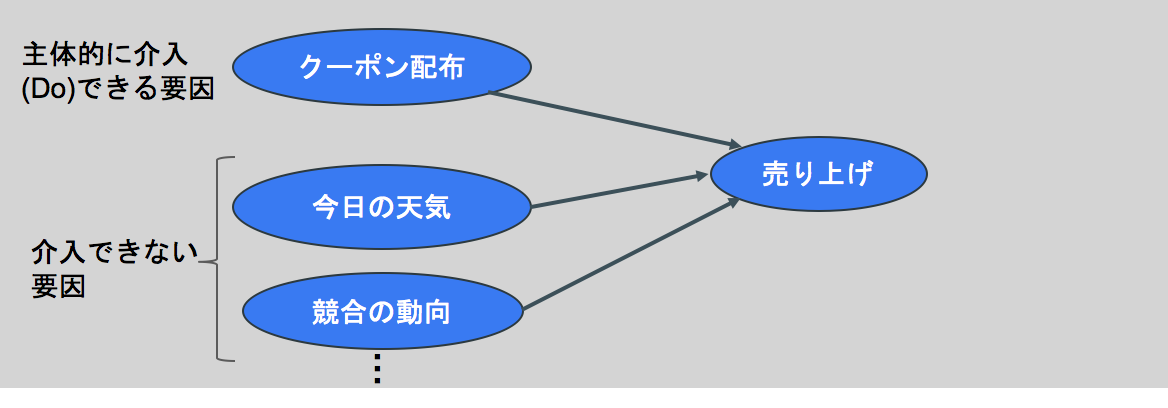
ある結果をもたらす要因には人が主体的に介入できるものとできないものがあります(上図参照)。 この中で、要因分析をする人が注目したいのは介入できる要因で、例えば「何をすれば売り上げアップに繋がるのか」を知ることが分析のゴールです。一方、予測モデルを作りたい人にとっては要因に介入できるかできないかはあまり問題ではなく、「いかに高い精度で来月の売り上げ金額を予測できるか」がゴールになるわけです。
要因分析の結果、介入できる要因に対して効果的なアクションが取られれば、従来の予測モデルの予測精度に影響してしまうかもしれません。したがって一般的には要因分析と予測モデル作成が同時に目的になることはありません。
因果と相関:要因分析の難しさは擬相関にあり
上の図で何気なく要因(例えばクーポン配布)から結果(売り上げ)へ矢線を引きましたが、要因分析/因果解析の分野では「要因→結果」のような図による表現が一般的に行われており、これを因果関係と呼びます。
ところで、プロ野球の個人打撃成績のデータを見ると、ホームランバッターほど三振数も多い正の相関関係が認められるそうです。(右下はイメージ図ですが)
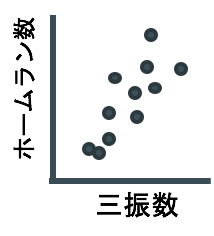
さて、この関係性を見て、「三振数→ホームラン数」の因果関係がある!と言えるでしょうか? つまり野球チームの監督がチームのホームラン数を増やすために選手に「もっと三振してこい」、と指示するでしょうか? もちろんそんな監督さんがもしいたら即解雇されるに違いありません。つまり、三振数とホームラン数には見かけの相関関係はあるが、因果関係があるとは考えられません。このように、本当は影響を与え合う関係ではないのに、あたかも関係性があるように見えていることを擬相関と呼びます。
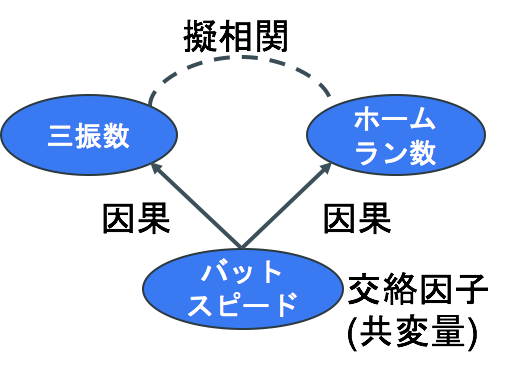 擬相関が起こるのは、左図のように三振数とホームラン数の両方に影響を与えている「第3の要因」が存在するためです(例えばバットスピード)。この第3の要因を、交絡(こうらく)因子(または共変量)と呼びます。交絡因子は、「要因(かどうかを知りたい対象」と「結果」の両方に影響を与える要因、と定義されます。
擬相関が起こるのは、左図のように三振数とホームラン数の両方に影響を与えている「第3の要因」が存在するためです(例えばバットスピード)。この第3の要因を、交絡(こうらく)因子(または共変量)と呼びます。交絡因子は、「要因(かどうかを知りたい対象」と「結果」の両方に影響を与える要因、と定義されます。
三振数とホームラン数のように、誰が見ても常識の範囲内で相関か因果かを見極められるなら良いのですが、現実世界では相関か因果かが簡単には判断できない複雑なケースがほとんどです。「風が吹けば桶屋が儲かる」と、多層的で複雑な因果関係のメカニズム(笑)をご隠居が明快に解説する落語がありますが、普通は多数の要因が複雑に絡み合った因果メカニズムを簡単には明らかにできません。様々な要因に関するデータを大量に収集できるようになってきた昨今では、なおさらでしょう。
実は、何も因果メカニズムを考えずに観測データだけから機械学習によって生成される予測モデルは、目的変数(ターゲット)と特徴量との相関関係を表しているだけで、因果関係、さらには、その要因に介入した時の「因果効果」を推定できるとは限りません。一方、要因分析を行う人の目標は介入による現状改善ですから、因果関係・因果効果を見つけなければいけなくて、ここにギャップがあります。
機械学習モデルから因果関係・因果効果を推定するには、因果メカニズムに関する因果仮説の作成やモデルに取り込む交絡因子の選択などの場面で、ドメイン知識の助けが必要です。一方で、例えばDataRobotであればどんなに複雑なモデルからも特徴量のインパクト情報を出力できるので、因果に迫るための実験や高度なデータ解析手法を使わなくても、ある程度のドメイン知識と組み合わせれば、介入するべき要因を見つけることも可能な場合が多いです。
また、多数の特徴量を取り込んで因果仮説を立てましょう、というのは非現実的ですから、一般的には要因分析の最初に「結果に対して本当に効いていると思われる少数の要因候補(Vital Few Features)」に特徴量を絞り込む作業(=特徴量選択)が必要になります。
 もし、数十、数百、数千の特徴量(要因候補)があって、その中からVital Few Features(VFFs)を見つけたいのであれば、統計的検定(Statistical test)でp値やF値を見ながら効いている要因を選択する伝統的な多変量解析のアプローチでは解が著しく不安定になる可能性があります。(理由の詳細は多変量解析の専門書に譲りますが、「多重検定」によって多くの誤った判断が為される可能性があったり、要因間の多重共線性(マルチコ)が影響して解が収束しない可能性があります)
もし、数十、数百、数千の特徴量(要因候補)があって、その中からVital Few Features(VFFs)を見つけたいのであれば、統計的検定(Statistical test)でp値やF値を見ながら効いている要因を選択する伝統的な多変量解析のアプローチでは解が著しく不安定になる可能性があります。(理由の詳細は多変量解析の専門書に譲りますが、「多重検定」によって多くの誤った判断が為される可能性があったり、要因間の多重共線性(マルチコ)が影響して解が収束しない可能性があります)また、特徴量の種類数がデータ数を上回る、いわゆる「横長データ」では、共分散行列の逆行列を計算して回帰係数を求めるような伝統的アプローチでは解を求めることすらできません。
これらの課題に対しては機械学習の適用が有効であり、特にDataRobotを使えば、Vital Few Featuresに要因候補を絞る作業(上図の「2.特徴量選択」)を、賢く安定的に行えます。具体的にどのようにやるのかは、山本さんのブログ(8/27公開)をご参照ください。
以上、今週は要因分析についてご紹介しました。次週は「機械学習を用いた要因分析-理論編 Part2」として、因果解析の基本理論を中心にご紹介する予定です。どうぞお楽しみに!
参考書籍
本ブログ作成にあたっては、下記書籍を参考にしました。要因分析/因果解析についてもっと勉強したいと思っている方に、2018年8月時点で最も推薦できる良書です。
- データ分析の力 因果関係に迫る思考法 (光文社新書), 伊藤 公一朗 (著)

- 岩波データサイエンス Vol.3, 岩波データサイエンス刊行委員会 (編集)



