AI活用のさらなるステージ:バイアスと公平性 Part 2
はじめに
DataRobotで主に政府公共領域やヘルスケア業界のお客様を担当しているデータサイエンティストの若月です。
本稿ではAIシステムのコアとなる機械学習モデルのバイアスと公平性に注目し、2回に渡って解説しています。Part 1では、以下のトピックを取り上げました。
- バイアスと公平性とは、その重要性
- バイアスの発生原因
- 公平性指標
Part 2では、モデルのバイアスを軽減するための具体的な手法や公平性に配慮したモデル構築をするためのプロジェクト体制について考察し、さらにDataRobotが標準的に備えている公平性評価・バイアス軽減のための機能をご紹介します。
モデルのバイアスを軽減する
Part 1でご紹介した公平性指標に基づいてモデルのバイアスが検知できたとして、そのモデルからバイアスを軽減するにはどうすれば良いのでしょうか。実は機械学習においてバイアスを軽減しうるタイミングは大きく分けて3つあります。
- データ準備段階でのバイアス軽減(Pre-Processing Bias Mitigation)
- 学習時のバイアス軽減(In-Processing Bias Mitigation)
- 予測時のバイアス軽減(Post-Processing Bias Mitigation)
それぞれにおいてさまざまな方法が提案されていますが、そのうちのいくつかをご紹介します。
データ準備段階でのバイアス軽減
- データの生成・収集プロセス自体の見直し
Part 1で述べたようにバイアスの発生はデータの生成・収集プロセスに起因しているので、そのプロセス自体を見直すことは根本的にバイアスを排除するのに最も効果的な手段となります。例えば数の少ない属性のデータを収集するのは、コストとのトレードオフになり、かつあらゆるケースで可能な方法ではないですが、実施できる場合にはとても有効です。
一方でPart 1で述べたように、ラベル付けなどデータ生成に人間の判断が含まれることがあるとその判断によってバイアスが入り込んでしまうのは避けられません。また、後述する方法とは異なりデータを収集し直す必要があることからコストや時間もかかるというデメリットがあります。
- 特徴量の選定・特徴量エンジニアリング
特徴量の見直しもバイアスの軽減に有効な場合もあります。ただし、ここで気をつけなければならないのは「バイアスと直接関係する特徴量だけを学習データから除いても本質的なバイアスを除去できるとは限らない」ということです。
例えば採用の選考モデルで求職者の性別をモデルの特徴量から除外しても、それ以外の特徴量が性別と何らかの形で関連している(プロキシ特徴量になっている)と、それらを用いて学習したモデルは性別という情報を暗に含んでいることになります。
ここで、後述のサンプリングの節でも説明している「保護された特徴量をターゲットとして予測モデルを作成」する手法を用いると、どういった特徴量が保護された特徴量に関連しているか理解することができます。
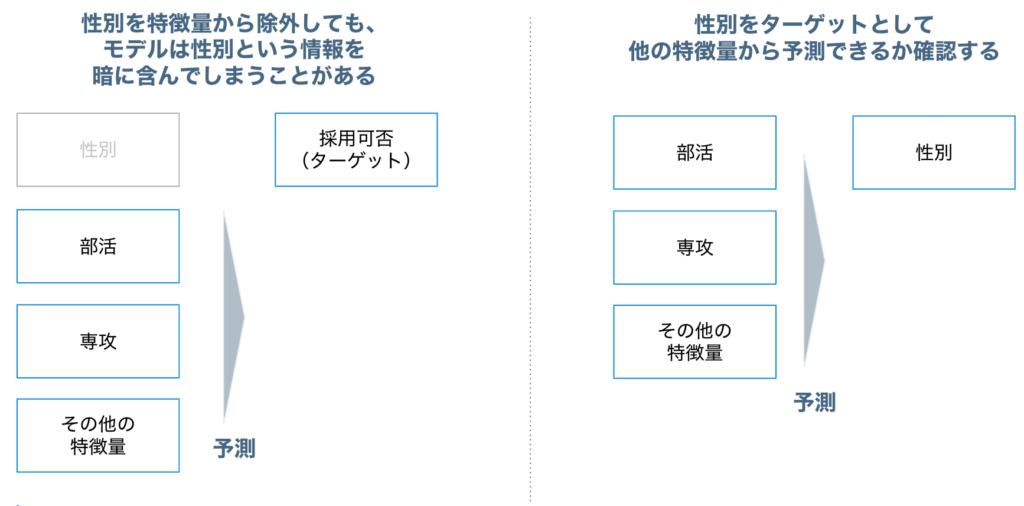
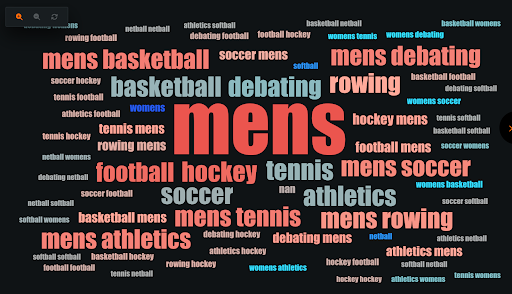
図1のような仮想例において、性別の予測モデルで部活の特徴量のインパクトがとても強く、部活について図2のようなワードクラウドがインサイトとして得られたとします。この場合には、例えばmens tennis/womens tennisといった単語をtennisに名寄せするなどの特徴量エンジニアリングを行う、といった方法も考えられるでしょう。
DataRobotを使えばこのような様々なモデリングも非常に簡単に行うことができる上、視覚的にも理解しやすい情報を提供してくれます。
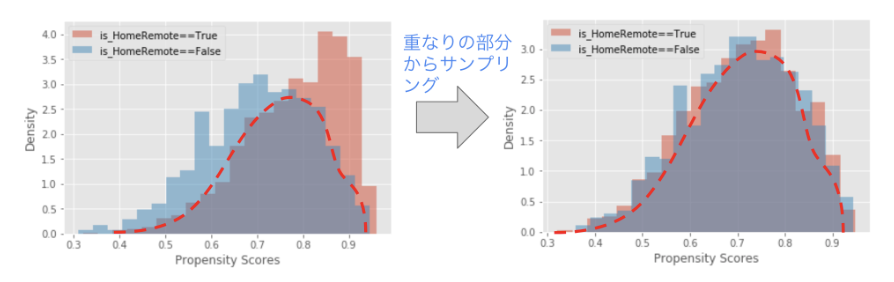
- サンプリング
手元のデータをそのまま全てモデリングに利用するのではなく、データ内のバイアスを軽減する目的でサンプリングを行います。サンプリングの方法としては、保護された特徴量をターゲットとして傾向スコアマッチングを行い、例えば男女間で近い特徴を持つデータのみを抽出してモデリングを行うなどが考えられます。ただし、サンプリングを行うことで意図しない別の観点でのバイアスが入り込む可能性も十分に考えられるため、注意して行う必要があります。(傾向スコアマッチングについては、弊社ブログの機械学習を用いた要因分析 – 実践編や機械学習を用いた要因分析 – 理論編 Part 2に詳細に解説されているため、ぜひご確認ください)
- 学習データの重み付け
例えば特定の属性のデータが少ない場合、その属性を重視するよう行ごとの重み付けを行うことでバイアスを軽減できる可能性があります。重み付けをするとその行が学習時に複数回現われるような挙動になりますが、詳細については弊社の過去のブログ記事もご参照ください。

学習時のバイアス軽減
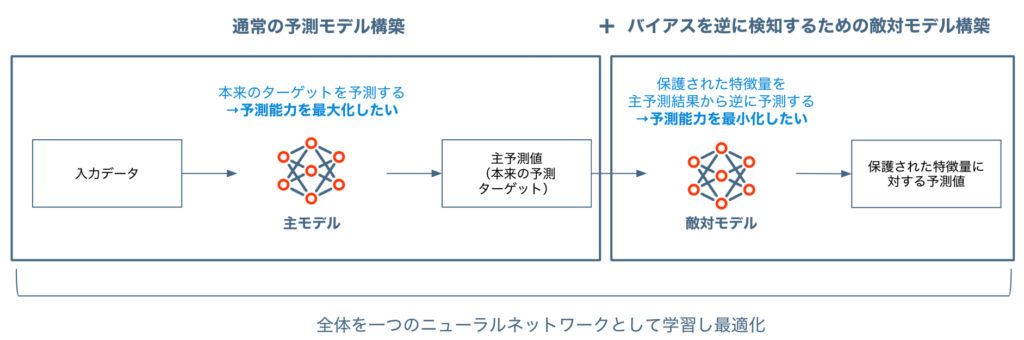
Adversarial Debiasing[1]
本来作りたい予測モデルに加え、その予測結果をもとに「保護された特徴量(=公平性を担保したいカテゴリ特徴量)」を予測する「敵対モデル(Adversary Model)」を作り、この二つのモデルの誤差からパラメータを更新する手法です(Generative Adversarial Networks[2], GANの考え方を取り入れています)。予測モデルの予測結果が完全に公平な”理想的”な状況では、敵対モデルの予測能力は限りなくランダムに近づくはずなので、予測モデルの誤差を最小化しつつ敵対モデルの誤差を最大化する最適な点を探します。このようなアプローチをとることで、精度とバイアス対処の両方を考慮したモデルを得ることができます。
予測時のバイアス軽減
- 閾値の調整
公平性指標として、Part 1で紹介した好ましいクラスの再現率を採用しているケースを想定してみましょう。二値分類の予測においては予測ラベルを決定するための閾値を決める必要がありますが、保護された特徴量のクラスごとに異なる閾値を設定することで、クラス間の公平性を改善できます。一方で公平性を担保するために閾値に手を加えると精度指標としてのモデルの再現率・適合率も変わるため、最終的な閾値はビジネス上求められる精度と公平性の2つの観点から決定する必要があります。
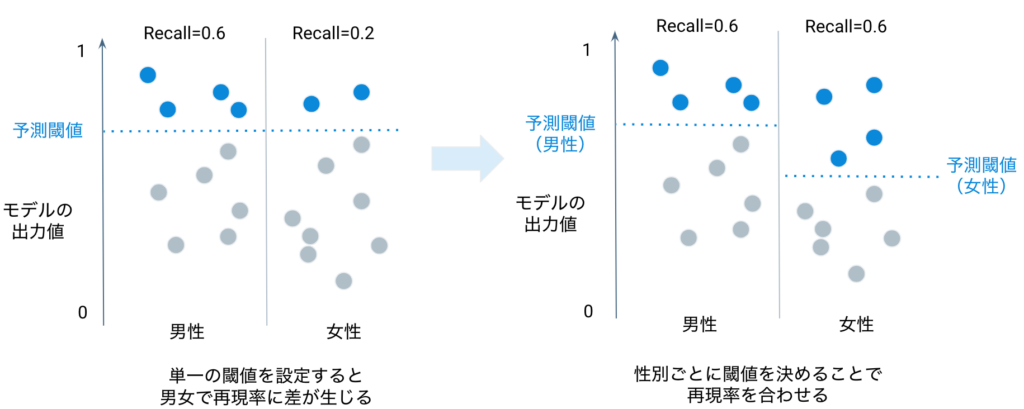
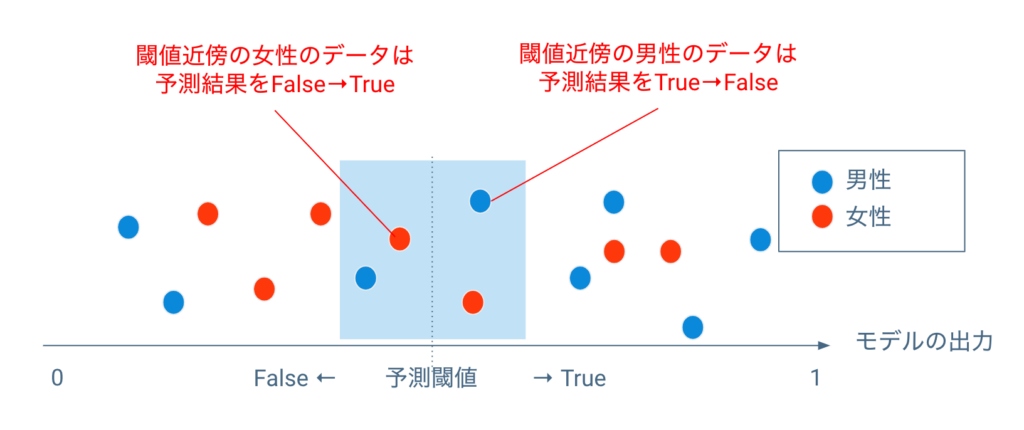
- Post-Processing Rejection Option-Based Classification[3]
分類問題において、「差別的な予測は予測閾値近傍のデータにおいて起こりやすい」という前提のもと、予測後に予測閾値近傍のデータ(予測結果)に対して予測ラベルを調整するという方法です。予測閾値付近のデータで下駄を履かせるなど調整をする、というとイメージしやすいかもしれません。
例えば採用の選考モデルで男性が女性よりも有利な予測をされているという状況の元で、予測閾値をわずかに下回った女性を採用(False → True)、予測閾値をわずかに上回った男性を不採用(True → False)、というように調整を行います。
実際のプロジェクトにおける留意点
公平性を欠いた機械学習モデルによるAIシステムが開発・運用されれば、プロジェクト中止や企業の社会的名声毀損など重大な結果につながる可能性があるのは本稿Part 1で述べた通りです。従って実際の機械学習プロジェクトにおいては、最初の企画段階でバイアスと公平性への留意点が漏れていないかプロジェクトメンバー間で議論することが必要です。さらには予測モデルで実現したい精度指標と同様に、バイアス評価を行うための公平性指標をプロジェクト毎に決定し、さらにモデルを実運用化する条件としてどの程度の値が求められるのかまで決定しておくべきです。
具体的な議論は機械学習プロジェクトのアイデアが固まり、詳細化していくフェーズにおいて行います。実務観点・データ観点双方から何に留意すべきか検討する必要がある以上、実務を十分に把握した分析担当者が議論をリードするのが理想的ではありますが、そのような知見・スキルを持ったメンバーがいなければ実務担当者と分析担当者が主体となって共同で議論を進める形をとることとなります。
しかし、プロジェクトを始める時点ではまだ具体的な問題点が判断できない、適切なバイアス評価方法が判断できない、といった状況であることも決して少なくないでしょう。その場合には、早期の段階からリスク管理担当者やコンプライアンス担当者をプロジェクトチームにアサインして、データ生成・収集プロセスやプロトタイプモデルのレビューに関わってもらう体制を持つことが推奨されます。
コンプライアンスの専門家による視点で公平性のリスクを早期に検知して対応すれば、プロジェクトの手戻りを防ぐことが期待できます。また、業界によっては関連する規制やガイドラインも存在しているので、それらを基準とすることもできます。例えば、米国では採用にあたりいわゆる”4/5ルール”が存在します。このルールに基づくと公平性指標指標としては「割合の平等性」を選択することになりますし、さらに指標としては低い方の値が0.8以上になることが求めらます。(公平性指標とその計算方法については本稿Part 1をご参照ください)
企業が組織的にAIを活用するステージになってくると、プロジェクトの進め方を組織内でテンプレート化することもあるかと思います。テンプレートの中にバイアスと公平性に関する議論並びに適切なメンバーによる承認を含めておくようにすれば、各プロジェクトにおいて議論が漏れる可能性を抑えられるでしょう。議論の主体となるのは先述のように業務担当者と分析担当者、承認者としては例えば各担当者の上長や独立したリスク管理担当者、コンプライアンス担当者などが考えられます。
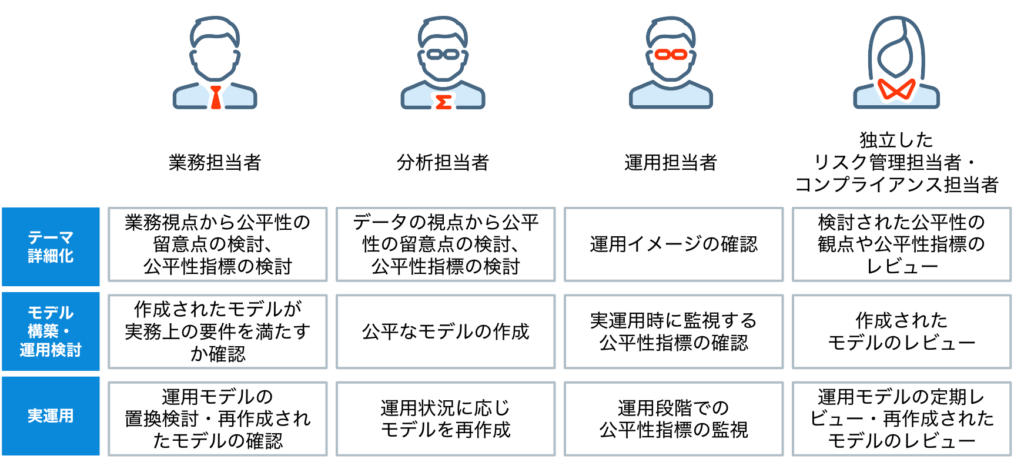
参考までに、「人」に関わる意思決定プロセスをAIで高度化することを目的としたプロジェクト(例えば下記)においては、バイアスと公平性の観点から特に注意を払う必要があります。
- 採用プロセスにおける書類選考のAIによる効率化
- 住宅ローンの審査業務の効率化
- 犯罪リスクの高い地域の可視化
- 児童虐待リスクの予測
- 介護のハイリスク者の抽出
DataRobotでできること
DataRobotでは二値分類のプロジェクトで公平性の評価とバイアス軽減を行えます(バイアス軽減については2022年12月現在、クラウド版のみでのご提供になります)。
これらはプロジェクトの開始前に「保護された特徴量」(=公平性を担保したいカテゴリ特徴量)を指定してから通常通りモデリングを行うだけで簡単に実施可能です。なお、バイアス軽減については先にご紹介した手法のうちデータ準備段階でのバイアス軽減として学習データの重み付けを、予測時のバイアス軽減としてPost-Processing Reject Option-Based Classification を利用でき、状況に応じて使い分けることができます。
具体的な操作手順や詳細は公式ドキュメントが詳しいのでそちらをご参照ください。
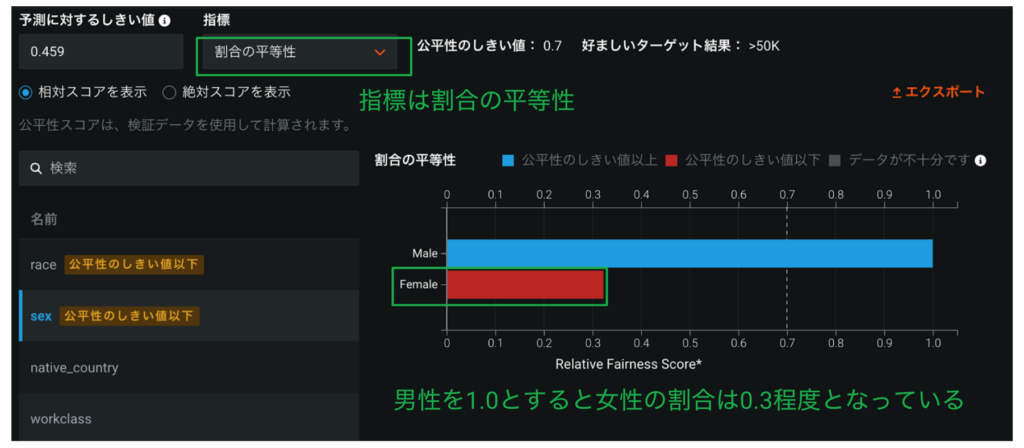
公平性指標の確認
Part 1で解説した公平性の指標に基づき、予測モデルの公平性をUI上で確認できます。プライマリーで適用する公平性指標はモデリング開始前に「高度なオプション」から設定が必要ですが、モデリング完了後にリーダーボードから個別のモデルについて他の各指標による評価も確認可能です。
下図は前述の賃金が高いか低いかを予測する二値分類モデルの例ですが、女性(赤い棒グラフ)は男性(青い棒グラフ)よりも”不利に”予測されていることがわかります。
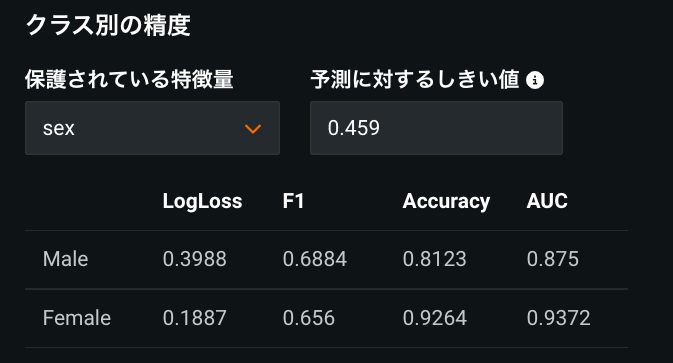
クラスごとの精度確認
リーダーボード上で、「保護された特徴量」の各カテゴリ値ごとに精度指標値が表示されるため、精度がクラス間で偏っていないかを確認できます。下図では男女それぞれについていくつかの精度指標で精度を表示しています。
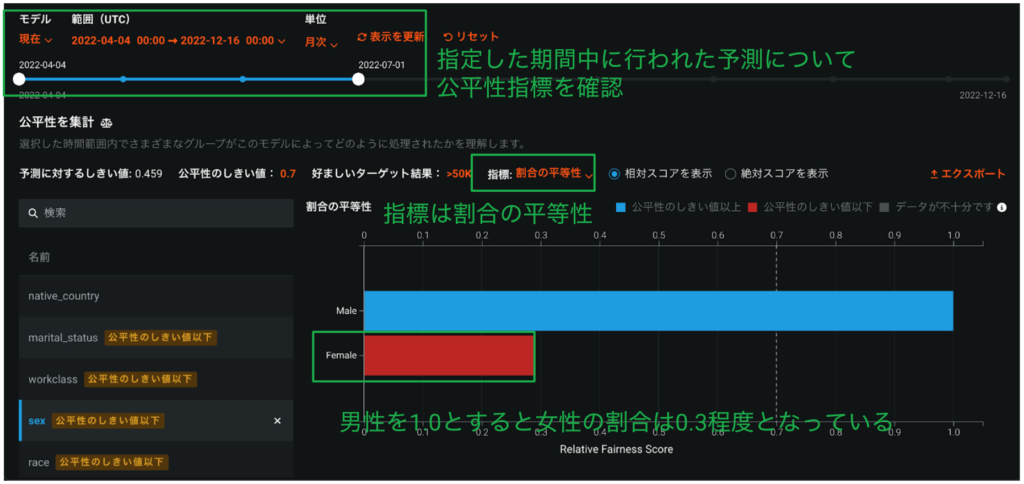
DataRobot MLOpsを用いた予測結果の公平性トラッキング
モデルのデプロイ後も、各デプロイに対して行われた予測に対して公平性指標を確認できます。こうして機械学習モデルが実運用ステージに入った後も”不公平な”予測が行われていないかをトラック可能です。
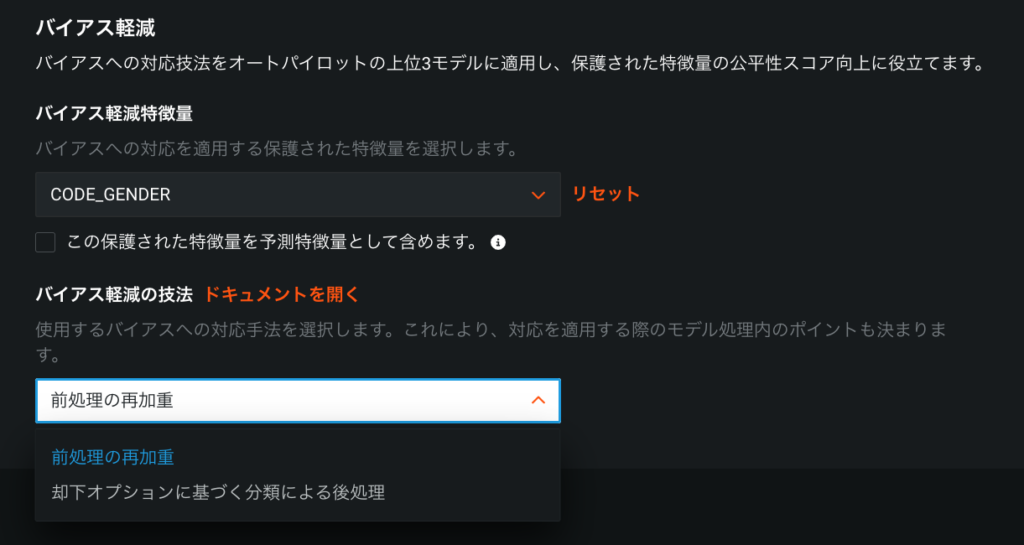
バイアス軽減
開始ボタンを押す前に、「高度なオプション」の「バイアスと公平性」から「プライマリー公平性指標」を選び、「バイアス軽減の技法」を「前処理の再加重」あるいは「 却下オプションに基づく分類による後処理」(Post-Processing Reject Option-Based Classification)から選択できます。
あとは通常通りモデリングを行うだけで、モデリング完了後、リーダーボードの上位モデルに対してバイアス軽減処理を施したモデルが自動的に作成されます。なおバイアス軽減オプションを使ったからといって、期待通りのバイアス軽減がなされているとは限らないため、必ず公平性指標の確認を行うことが必要です。

以上のように、DataRobotを使うと公平性指標の計算・確認やバイアス軽減といった公平性の高いモデル作成に必要なタスクも特別なコーディングを要することなく簡単に行うことができます。もちろんモデルの構築も含め自動で行ってくれるので、機械学習プロジェクトメンバーは『公平性をどのように評価するか、どのようにバイアスに対処するか』のような、人間にしかできない重要な検討項目にフォーカスできます。
まとめ
本稿Part 1では
- バイアスと公平性とは、その重要性
- バイアスの発生原因
- 公平性指標
Part 2では
- バイアス軽減のさまざまな手法
- 実際の機械学習プロジェクト推進における留意点
- モデルのバイアスに対してDataRobotができること
を幅広くご紹介しました。繰り返しになりますが、公平性の観点は一つではないので、プロジェクトの特性に応じて対処方法を選定することが必要です。冒頭で述べたように、AIを幅広い業務で活用するのが当たり前になってきている今こそ、バイアスの小さな機械学習モデルをあらゆるレイヤーで作っていけるよう組織・体制を構築していくことが求められています。
一方、全てのプロジェクトで、上記指標の確認やバイアスを軽減したモデリングを分析者に求めたとしても、それら分析は実装の観点で障壁が高いことも事実です。DataRobotでは、誰でも簡単に、全てのプロジェクトでバイアスの確認やバイアス低減のための実装を行うことができます。バイアスに関する理解と、実装を可能にするプラットフォームで、次の時代に求められるAIプロジェクトを一緒に進めていきましょう。
参考文献
[1] B. H. Zhang, B. Lemoine, and M. Mitchell, “Mitigating Unwanted Biases with Adversarial Learning”, AIES ’18: Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 2018
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, “Generative Adversarial Nets”, Advances in Neural Information Processing Systems 27 (NIPS 2014), 2014
[3] Kamiran, F., Karim, A., Zhang, X, “Decision theory for discrimination-aware classification”, 2012 IEEE International Conference on Data Mining (ICDM 2012), 2012


