Harnessing Synthetic Data for Model Training
It is no secret to anyone that high-performing ML models have to be supplied with large volumes of quality training data. Without having the data, there’s hardly a way an organization can leverage AI and self-reflect to become more efficient and make better-informed decisions. The process of becoming a data-driven (and especially AI-driven) company is known to be not easy.
28% of companies that adopt AI cite lack of access to data as a reason behind failed deployments. – KDNuggets
Additionally, there are issues with errors and biases within existing data. They are somewhat easier to mitigate by various processing techniques, but this still affects the availability of trustworthy training data. It’s a serious problem, but the lack of training data is a much harder problem, and solving it might involve many initiatives depending on the maturity level.
Besides data availability and biases there’s another aspect that is very important to mention: data privacy. Both companies and individuals are consistently choosing to prevent data they own to be used for model training by third parties. The lack of transparency and legislation around this topic is well known and had already become a catalyst of lawmaking across the globe.
However, in the broad landscape of data-oriented technologies, there’s one that aims to solve the above-mentioned problems from a little unexpected angle. This technology is synthetic data. Synthetic data is produced by simulations with various models and scenarios or sampling techniques of existing data sources to create new data that is not sourced from the real world.
Synthetic data can replace or augment existing data and be used for training ML models, mitigating bias, and protecting sensitive or regulated data. It is cheap and can be produced on demand in large quantities according to specified statistics.
Synthetic datasets keep the statistical properties of the original data used as a source: techniques that generate the data obtain a joint distribution that also can be customized if necessary. As a result, synthetic datasets are similar to their real sources but don’t contain any sensitive information. This is especially useful in highly regulated industries such as banking and healthcare, where it can take months for an employee to get access to sensitive data because of strict internal procedures. Using synthetic data in this environment for testing, training AI models, detecting fraud and other purposes simplifies the workflow and reduces the time required for development.
All this also applies to training large language models since they are trained mostly on public data (e.g. OpenAI ChatGPT was trained on Wikipedia, parts of web index, and other public datasets), but we think that it is synthetic data is a real differentiator going further since there’s a limit of available public data for training models (both physical and legal) and human created data is expensive, especially if it requires experts.
Producing Synthetic Data
There are various methods of producing synthetic data. They can be subdivided into roughly 3 major categories, each with its advantages and disadvantages:
- Stochastic process modeling. Stochastic models are relatively simple to build and don’t require a lot of computing resources, but since modeling is focused on statistical distribution, the row-level data has no sensitive information. The simplest example of stochastic process modeling can be generating a column of numbers based on some statistical parameters such as minimum, maximum, and average values and assuming the output data follows some known distribution (e.g. random or Gaussian).
- Rule-based data generation. Rule-based systems improve statistical modeling by including data that is generated according to rules defined by humans. Rules can be of various complexity, but high-quality data requires complex rules and tuning by human experts which limits the scalability of the method.
- Deep learning generative models. By applying deep learning generative models, it is possible to train a model with real data and use that model to generate synthetic data. Deep learning models are able to capture more complex relationships and joint distributions of datasets, but at a higher complexity and compute costs.
Also, it is worth mentioning that current LLMs can also be used to generate synthetic data. It does not require extensive setup and can be very useful on a smaller scale (or when done just on a user request) as it can provide both structured and unstructured data, but on a larger scale it might be more expensive than specialized methods. Let’s not forget that state-of-the-art models are prone to hallucinations so statistical properties of synthetic data that comes from LLM should be checked before using it in scenarios where distribution matters.
An interesting example that can serve as an illustration of how the use of synthetic data requires a change in approach to ML model training is an approach to model validation.
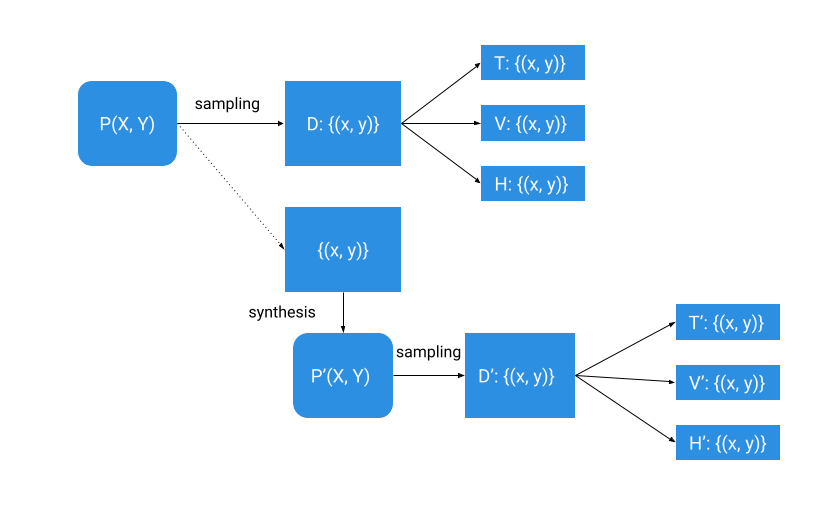
In traditional data modeling, we have a dataset (D) that is a set of observations drawn from some unknown real-world process (P) that we want to model. We divide that dataset into a training subset (T), a validation subset (V) and a holdout (H) and use it to train a model and estimate its accuracy.
To do synthetic data modeling, we synthesize a distribution P’ from our initial dataset and sample it to get the synthetic dataset (D’). We subdivide the synthetic dataset into a training subset (T’), a validation subset (V’), and a holdout (H’) like we subdivided the real dataset. We want distribution P’ to be as practically close to P as possible since we want the accuracy of a model trained on synthetic data to be as close to the accuracy of a model trained on real data (of course, all synthetic data guarantees should be held).
When possible, synthetic data modeling should also use the validation (V) and holdout (H) data from the original source data (D) for model evaluation to ensure that the model trained on synthetic data (T’) performs well on real-world data.
So, a good synthetic data solution should allow us to model P(X, Y) as accurately as possible while keeping all privacy guarantees held.
Although the wider use of synthetic data for model training requires changing and improving existing approaches, in our opinion, it is a promising technology to address current problems with data ownership and privacy. Its proper use will lead to more accurate models that will improve and automate the decision making process significantly reducing the risks associated with the use of private data.
Nick Volynets is a senior data engineer working with the office of the CTO where he enjoys being at the heart of DataRobot innovation. He is interested in large scale machine learning and passionate about AI and its impact.
-
The enterprise path to agentic AI
April 9| 15 min read -
DataRobot with NVIDIA: The fastest path to production-ready AI apps and agents
March 18| 5 min read -
Talk to My Data: Instant, explainable answers with agentic AI
March 13| 6 min read
Latest posts

