Empowering AI builders with advanced LLM evaluation and assessment metrics
In the rapidly evolving landscape of Generative AI (GenAI), data scientists and AI builders are constantly seeking powerful tools to create innovative applications using Large Language Models (LLMs). DataRobot has introduced a suite of advanced LLM evaluation, testing, and assessment metrics in their Playground, offering unique capabilities that set it apart from other platforms.
These metrics, including faithfulness, correctness, citations, Rouge-1, cost, and latency, provide a comprehensive and standardized approach to validating the quality and performance of GenAI applications. By leveraging these metrics, customers and AI builders can develop reliable, efficient, and high-value GenAI solutions with increased confidence, accelerating their time-to-market and gaining a competitive edge. In this blog post, we will take a deep dive into these metrics and explore how they can help you unlock the full potential of LLMs within the DataRobot platform.
Exploring Comprehensive Evaluation Metrics
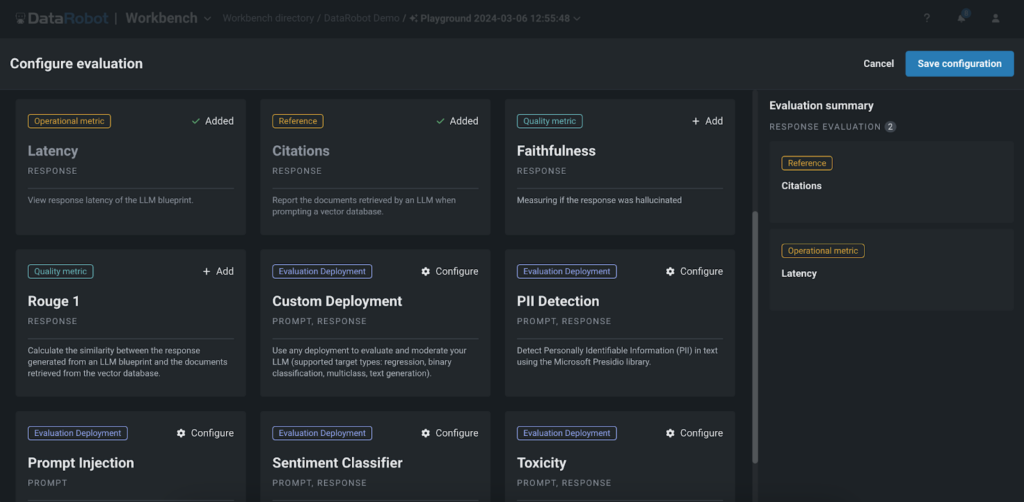
DataRobot’s Playground offers a comprehensive set of evaluation metrics that allow users to benchmark, compare performance, and rank their Retrieval-Augmented Generation (RAG) experiments. These metrics include:
- Faithfulness: This metric evaluates how accurately the responses generated by the LLM reflect the data sourced from the vector databases, ensuring the reliability of the information.
- Correctness: By comparing the generated responses with the ground truth, the correctness metric assesses the accuracy of the LLM’s outputs. This is particularly valuable for applications where precision is critical, such as in healthcare, finance, or legal domains, enabling customers to trust the information provided by the GenAI application.
- Citations: This metric tracks the documents retrieved by the LLM when prompting the vector database, providing insights into the sources used to generate the responses. It helps users ensure that their application is leveraging the most appropriate sources, enhancing the relevance and credibility of the generated content.The Playground’s guard models can assist in verifying the quality and relevance of the citations used by the LLMs.
- Rouge-1: The Rouge-1 metric calculates the overlap of unigram (each word) between the generated response and the documents retrieved from the vector databases, allowing users to evaluate the relevance of the generated content.
- Cost and Latency: We also provide metrics to track the cost and latency associated with running the LLM, enabling users to optimize their experiments for efficiency and cost-effectiveness. These metrics help organizations find the right balance between performance and budget constraints, ensuring the feasibility of deploying GenAI applications at scale.
- Guard models: Our platform allows users to apply guard models from the DataRobot Registry or custom models to assess LLM responses. Models like toxicity and PII detectors can be added to the playground to evaluate each LLM output. This enables easy testing of guard models on LLM responses before deploying to production.
Efficient Experimentation
DataRobot’s Playground empowers customers and AI builders to experiment freely with different LLMs, chunking strategies, embedding methods, and prompting methods. The assessment metrics play a crucial role in helping users efficiently navigate this experimentation process. By providing a standardized set of evaluation metrics, DataRobot enables users to easily compare the performance of different LLM configurations and experiments. This allows customers and AI builders to make data-driven decisions when selecting the best approach for their specific use case, saving time and resources in the process.
For example, by experimenting with different chunking strategies or embedding methods, users have been able to significantly improve the accuracy and relevance of their GenAI applications in real-world scenarios. This level of experimentation is crucial for developing high-performing GenAI solutions tailored to specific industry requirements.
Optimization and User Feedback
The assessment metrics in Playground act as a valuable tool for evaluating the performance of GenAI applications. By analyzing metrics such as Rouge-1 or citations, customers and AI builders can identify areas where their models can be improved, such as enhancing the relevance of generated responses or ensuring that the application is leveraging the most appropriate sources from the vector databases. These metrics provide a quantitative approach to assessing the quality of the generated responses.
In addition to the assessment metrics, DataRobot’s Playground allows users to provide direct feedback on the generated responses through thumbs up/down ratings. This user feedback is the primary method for creating a fine-tuning dataset. Users can review the responses generated by the LLM and vote on their quality and relevance. The up-voted responses are then used to create a dataset for fine-tuning the GenAI application, enabling it to learn from the user’s preferences and generate more accurate and relevant responses in the future. This means that users can collect as much feedback as needed to create a comprehensive fine-tuning dataset that reflects real-world user preferences and requirements.
By combining the assessment metrics and user feedback, customers and AI builders can make data-driven decisions to optimize their GenAI applications. They can use the metrics to identify high-performing responses and include them in the fine-tuning dataset, ensuring that the model learns from the best examples. This iterative process of evaluation, feedback, and fine-tuning enables organizations to continuously improve their GenAI applications and deliver high-quality, user-centric experiences.
Synthetic Data Generation for Rapid Evaluation
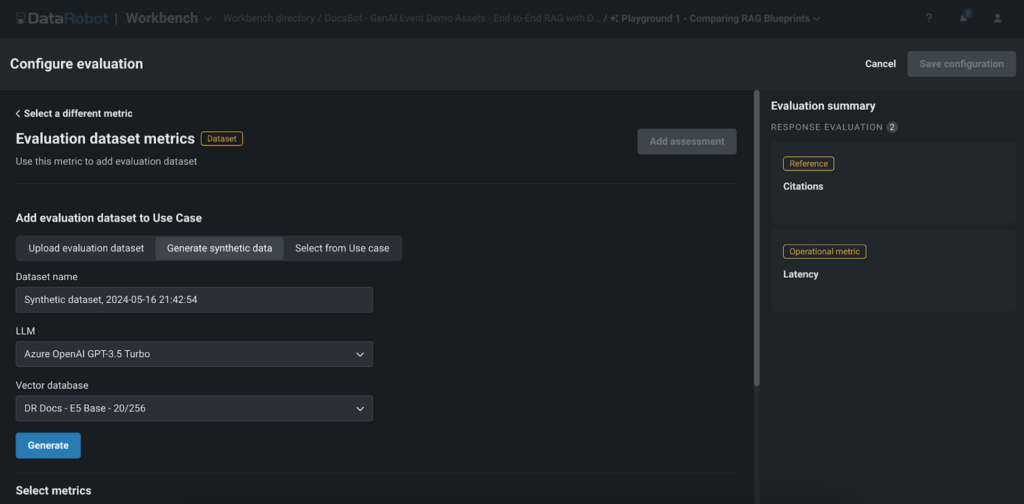
One of the standout features of DataRobot’s Playground is the synthetic data generation for prompt-and-answer evaluation. This feature allows users to quickly and effortlessly create question-and-answer pairs based on the user’s vector database, enabling them to thoroughly evaluate the performance of their RAG experiments without the need for manual data creation.
Synthetic data generation offers several key benefits:
- Time-saving: Creating large datasets manually can be time-consuming. DataRobot’s synthetic data generation automates this process, saving valuable time and resources, and allowing customers and AI builders to rapidly prototype and test their GenAI applications.
- Scalability: With the ability to generate thousands of question-and-answer pairs, users can thoroughly test their RAG experiments and ensure robustness across a wide range of scenarios. This comprehensive testing approach helps customers and AI builders deliver high-quality applications that meet the needs and expectations of their end-users.
- Quality assessment: By comparing the generated responses with the synthetic data, users can easily evaluate the quality and accuracy of their GenAI application. This accelerates the time-to-value for their GenAI applications, enabling organizations to bring their innovative solutions to market more quickly and gain a competitive edge in their respective industries.
It’s important to consider that while synthetic data provides a quick and efficient way to evaluate GenAI applications, it may not always capture the full complexity and nuances of real-world data. Therefore, it’s crucial to use synthetic data in conjunction with real user feedback and other evaluation methods to ensure the robustness and effectiveness of the GenAI application.
Conclusion
DataRobot’s advanced LLM evaluation, testing, and assessment metrics in Playground provide customers and AI builders with a powerful toolset to create high-quality, reliable, and efficient GenAI applications. By offering comprehensive evaluation metrics, efficient experimentation and optimization capabilities, user feedback integration, and synthetic data generation for rapid evaluation, DataRobot empowers users to unlock the full potential of LLMs and drive meaningful results.
With increased confidence in model performance, accelerated time-to-value, and the ability to fine-tune their applications, customers and AI builders can focus on delivering innovative solutions that solve real-world problems and create value for end users.
Evaluation and assessment metrics for LLMs are critical, yet hallucinations remain a key challenge. To learn how to assess and manage them effectively, check out our on-demand webinar, Conquering the Risk of LLM Hallucinations.


Nathaniel Daly is a Senior Product Manager at DataRobot focusing on AutoML and time series products. He’s focused on bringing advances in data science to users such that they can leverage this value to solve real world business problems. He holds a degree in Mathematics from University of California, Berkeley.
-
The enterprise path to agentic AI
April 9| 15 min read -
DataRobot with NVIDIA: The fastest path to production-ready AI apps and agents
March 18| 5 min read -
Talk to My Data: Instant, explainable answers with agentic AI
March 13| 6 min read
Latest posts

