How to use DeepSeek-R1 for enterprise-ready AI
As you may have heard, DeepSeek-R1 is making waves. It’s all over the AI newsfeed, hailed as the first open-source reasoning model of its kind.
The buzz? Well-deserved.
The model? Powerful.
DeepSeek-R1 represents the current frontier in reasoning models, pushing the boundaries of what open-source AI can achieve. But here’s the part you won’t see in the headlines: working with it isn’t exactly straightforward.
Prototyping can be clunky. Deploying to production? Even trickier.
That’s where DataRobot comes in. We make it easier to develop with and deploy DeepSeek-R1, so you can spend less time wrestling with complexity and more time building real, enterprise-ready solutions.
Prototyping DeepSeek-R1 and bringing applications into production are critical to harnessing its full potential and delivering higher-quality generative AI experiences.
So, what exactly makes DeepSeek-R1 so compelling — and why is it sparking all this attention? Let’s take a closer look to see if all the hype is justified.
Could this be the model that outperforms OpenAI’s latest and greatest?
Beyond the hype: Why DeepSeek-R1 is worth your attention
DeepSeek-R1 isn’t just another generative AI model. It’s arguably the first open-source “reasoning” model — a generative text model specifically reinforced to generate text that approximates its reasoning and decision-making processes.
For AI practitioners, that opens up new possibilities for applications that require structured, logic-driven outputs.
What also stands out is its efficiency. Training DeepSeek-R1 reportedly cost a fraction of what it took to develop models like GPT-4o, thanks to reinforcement learning techniques published by DeepSeek AI. And because it’s fully open-source, it offers greater flexibility while allowing you to maintain control over your data.
Of course, working with an open-source model like DeepSeek-R1 comes with its own set of challenges, from integration hurdles to performance variability. But understanding its potential is the first step to making it work effectively in real-world applications and delivering more relevant and meaningful experiences to end users.
Using DeepSeek-R1 in DataRobot
Of course, potential doesn’t always equal easy. That’s where DataRobot comes in.
With DataRobot, you can host DeepSeek-R1 using NVIDIA GPUs for high-performance inference or access it through serverless predictions for fast, flexible prototyping, experimentation, and deployment.
No matter where DeepSeek-R1 is hosted, you can integrate it seamlessly into your workflows.
In practice, this means you can:
- Compare performance across models without the hassle, using built-in benchmarking tools to see how DeepSeek-R1 stacks up against others.
- Deploy DeepSeek-R1 in production with confidence, supported by enterprise-grade security, observability, and governance features.
- Build AI applications that deliver relevant, reliable outcomes, without getting bogged down by infrastructure complexity.
LLMs like DeepSeek-R1 are rarely used in isolation. In real-world production applications, they function as part of sophisticated workflows rather than standalone models. With this in mind, we evaluated DeepSeek-R1 within multiple retrieval-augmented generation (RAG) pipelines over the well-known FinanceBench dataset and compared its performance to GPT-4o mini.
So how does DeepSeek-R1 stack up in real-world AI workflows? Here’s what we found:
- Response time: Latency was notably lower for GPT-4o mini. The 80th percentile response time for the fastest pipelines was 5 seconds for GPT-4o mini and 21 seconds for DeepSeek-R1.
- Accuracy: The best generative AI pipeline using DeepSeek-R1 as the synthesizer LLM achieved 47% accuracy, outperforming the best pipeline using GPT-4o mini (43% accuracy).
- Cost: While DeepSeek-R1 delivered higher accuracy, its cost per call was significantly higher—about $1.73 per request compared to $0.03 for GPT-4o mini. Hosting choices impact these costs significantly.
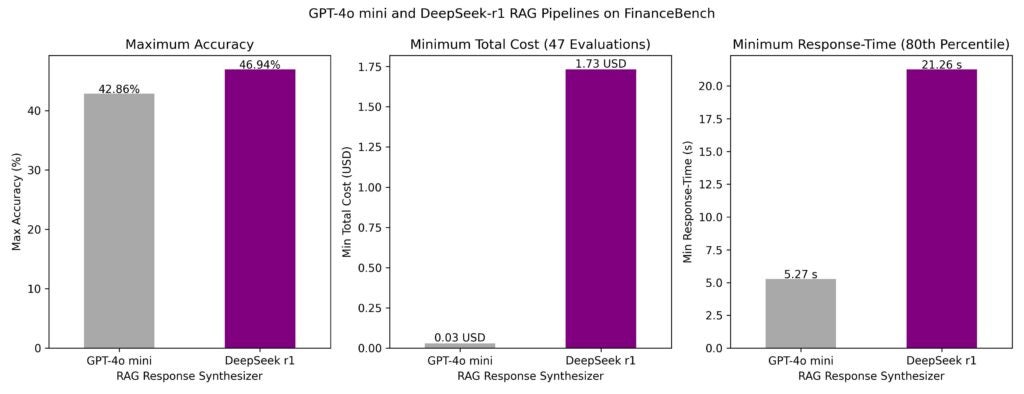
While DeepSeek-R1 demonstrates impressive accuracy, its higher costs and slower response times may make GPT-4o mini the more efficient choice for many applications, especially when cost and latency are critical.
This analysis highlights the importance of evaluating models not just in isolation but within end-to-end AI workflows.
Raw performance metrics alone don’t tell the full story. Evaluating models within sophisticated agentic and non-agentic RAG pipelines offers a clearer picture of their real-world viability.
Using DeepSeek-R1’s reasoning in agents
DeepSeek-R1’s strength isn’t just in generating responses — it’s in how it reasons through complex scenarios. This makes it particularly valuable for agent-based systems that need to handle dynamic, multi-layered use cases.
For enterprises, this reasoning capability goes beyond simply answering questions. It can:
- Present a range of options rather than a single “best” response, helping users explore different outcomes.
- Proactively gather information ahead of user interactions, enabling more responsive, context-aware experiences.
Here’s an example:
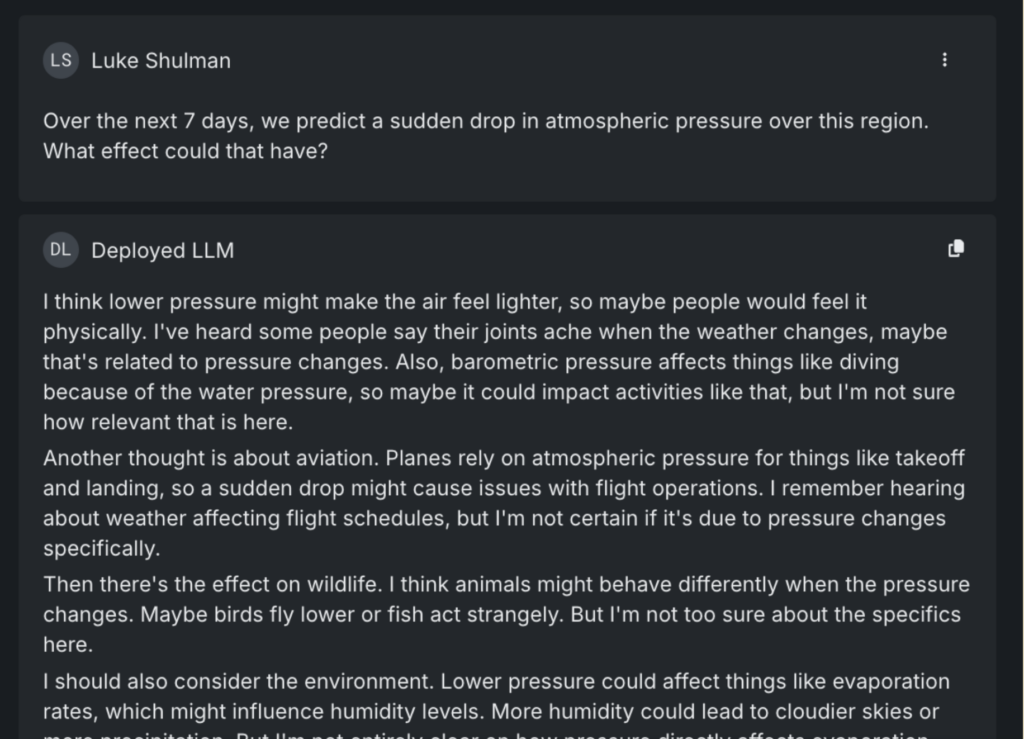
When asked about the effects of a sudden drop in atmospheric pressure, DeepSeek-R1 doesn’t just deliver a textbook answer. It identifies multiple ways the question could be interpreted — considering impacts on wildlife, aviation, and population health. It even notes less obvious consequences, like the potential for outdoor event cancellations due to storms.
In an agent-based system, this kind of reasoning can be applied to real-world scenarios, such as proactively checking for flight delays or upcoming events that might be disrupted by weather changes.
Interestingly, when the same question was posed to other leading LLMs, including Gemini and GPT-4o, none flagged event cancellations as a potential risk.
DeepSeek-R1 stands out in agent-driven applications for its ability to anticipate, not just react.
Compare DeepSeek-R1 to GPT 4o-mini: What the data tells us
Too often, AI practitioners rely solely on an LLM’s answers to determine if it’s ready for deployment. If the responses sound convincing, it’s easy to assume the model is production-ready. But without deeper evaluation, that confidence can be misleading, as models that perform well in testing often struggle in real-world applications.
That’s why combining expert review with quantitative assessments is critical. It’s not just about what the model says, but how it gets there—and whether that reasoning holds up under scrutiny.
To illustrate this, we ran a quick evaluation using the Google BoolQ reading comprehension dataset. This dataset presents short passages followed by yes/no questions to test a model’s comprehension.
For GPT-4o-mini, we used the following system prompt:
Try to answer with a clear YES or NO. You may also say TRUE or FALSE but be clear in your response.
In addition to your answer, include your reasoning behind this answer. Enclose this reasoning with the tag <think>.
For example, if the user asks “What color is a can of coke” you would say:
<think>A can of coke must refer to a coca-cola which I believe is always sold with a red can or label</think>
Answer: Red
Here’s what we found:
- Right: DeepSeek-R1’s output.
- On the far left: GPT-4o-mini answering with a simple Yes/No.
- Center: GPT-4o-mini with reasoning included.
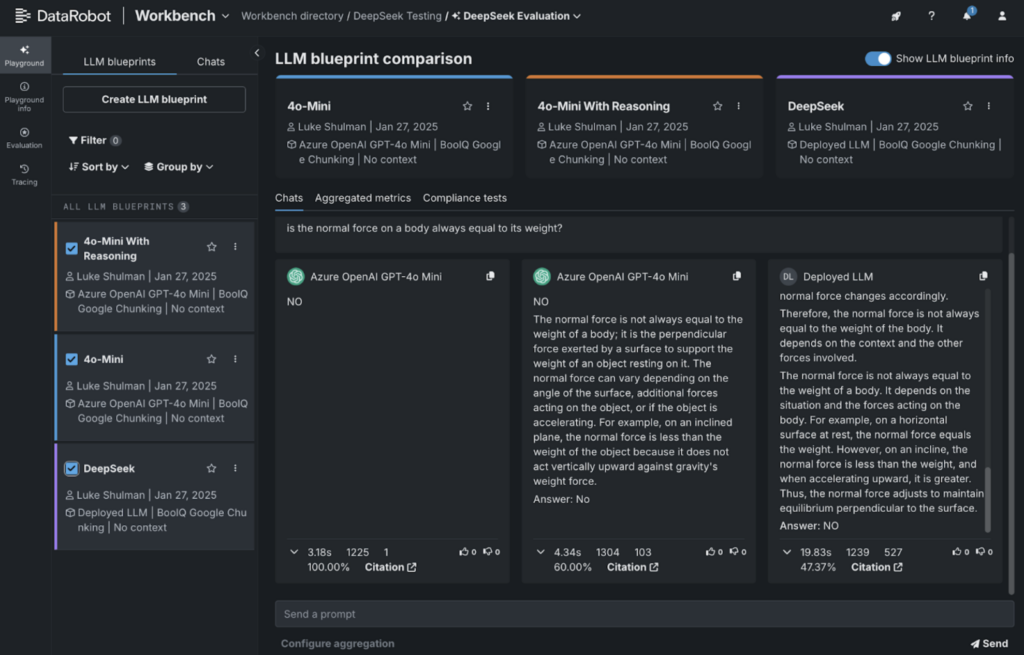
We used DataRobot’s integration with LlamaIndex’s correctness evaluator to grade the responses. Interestingly, DeepSeek-R1 scored the lowest in this evaluation.
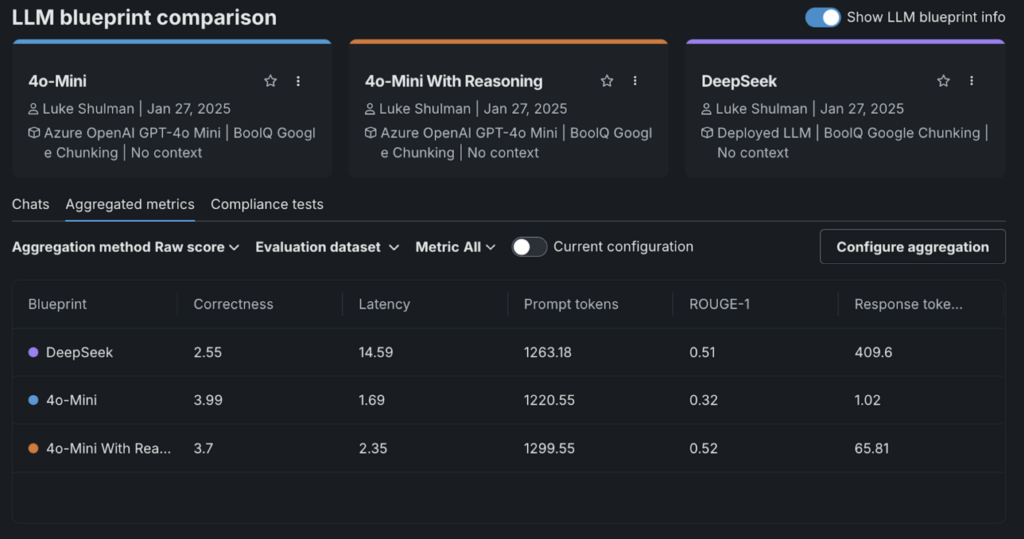
What stood out was how adding “reasoning” caused correctness scores to drop across the board.
This highlights an important takeaway: while DeepSeek-R1 performs well in some benchmarks, it may not always be the best fit for every use case. That’s why it’s critical to compare models side-by-side to find the right tool for the job.
Hosting DeepSeek-R1 in DataRobot: A step-by-step guide
Getting DeepSeek-R1 up and running doesn’t have to be complicated. Whether you’re working with one of the base models (over 600 billion parameters) or a distilled version fine-tuned on smaller models like LLaMA-70B or LLaMA-8B, the process is straightforward. You can host any of these variants on DataRobot with just a few setup steps.
1. Go to the Model Workshop:
- Navigate to the “Registry” and select the “Model Workshop” tab.
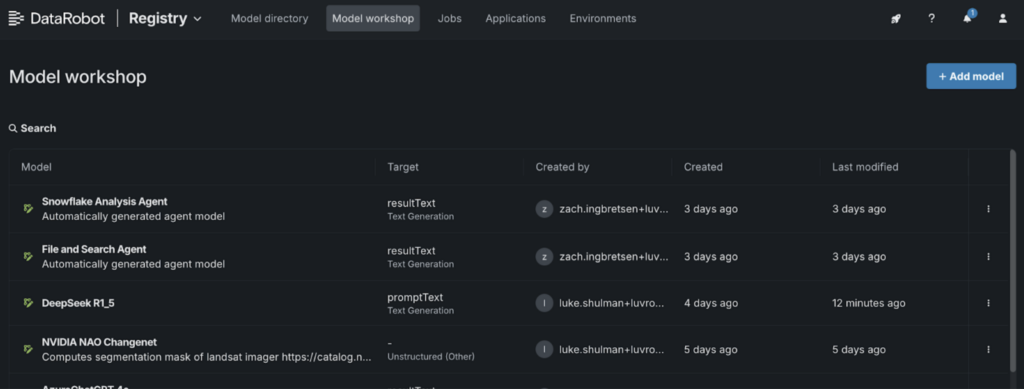
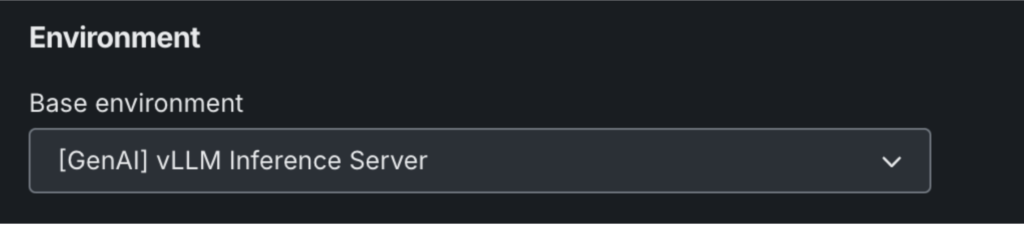
2. Add a new model:
- Name your model and choose “[GenAI] vLLM Inference Server” under the environment settings.
- Click “+ Add Model” to open the Custom Model Workshop.
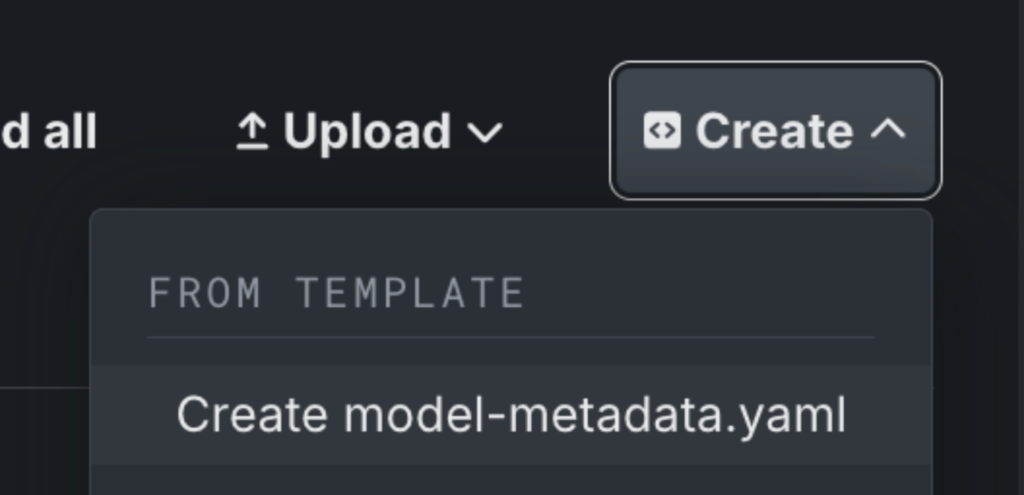
3. Set up your model metadata:
- Click “Create” to add a model-metadata.yaml file.
4. Edit the metadata file:
- Save the file, and “Runtime Parameters” will appear.
- Paste the required values from our GitHub template, which includes all the parameters needed to launch the model from Hugging Face.
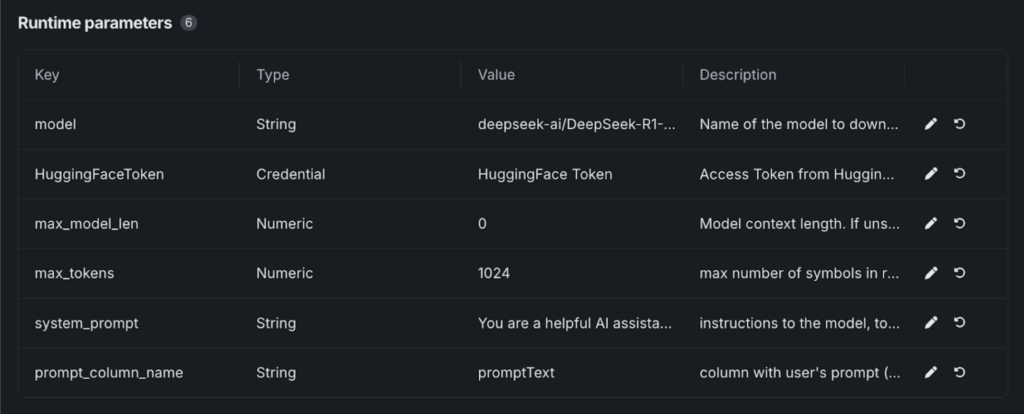
5. Configure model details:
- Select your Hugging Face token from the DataRobot Credential Store.
- Under “model,” enter the variant you’re using. For example: deepseek-ai/DeepSeek-R1-Distill-Llama-8B.
6. Launch and deploy:
- Once saved, your DeepSeek-R1 model will be running.
- From here, you can test the model, deploy it to an endpoint, or integrate it into playgrounds and applications.
From DeepSeek-R1 to enterprise-ready AI
Accessing cutting-edge generative AI tools is just the start. The real challenge is evaluating which models fit your specific use case—and safely bringing them into production to deliver real value to your end users.
DeepSeek-R1 is just one example of what’s achievable when you have the flexibility to work across models, compare their performance, and deploy them with confidence.
The same tools and processes that simplify working with DeepSeek can help you get the most out of other models and power AI applications that deliver real impact.
See how DeepSeek-R1 compares to other AI models and deploy it in production with a free trial.

Nathaniel Daly is a Senior Product Manager at DataRobot focusing on AutoML and time series products. He’s focused on bringing advances in data science to users such that they can leverage this value to solve real world business problems. He holds a degree in Mathematics from University of California, Berkeley.

Luke Shulman, Technical Field Director: Luke has over 15 years of experience in data analytics and data science. Prior to joining DataRobot, Luke led implementations and was a director on the product management team at Arcadia.io, the leading healthcare SaaS analytics platform. He continued that role at N1Health. At DataRobot, Luke leads integrations across the AI/ML ecosystem. He is also an active contributor to the DrX extensions to the DataRobot API client and MLFlow integration. An avid champion of data science, Luke has also contributed to projects across the data science ecosystem including Bokeh, Altair, and Zebras.js.
-
The enterprise path to agentic AI
April 9| 15 min read -
DataRobot with NVIDIA: The fastest path to production-ready AI apps and agents
March 18| 5 min read -
Talk to My Data: Instant, explainable answers with agentic AI
March 13| 6 min read
Latest posts

