DataRobot Notebooks: Enhanced Code-First Experience for Rapid AI Experimentation

Most, if not all, machine learning (ML) models in production today were born in notebooks before they were put into production. ML model builders spend a ton of time running multiple experiments in a data science notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption.
42% of data scientists are solo practitioners or on teams of five or fewer people. Data science teams of all sizes need a productive, collaborative method for rapid AI experimentation.
The new DataRobot Notebooks offering plays a crucial role in providing a collaborative environment for AI builders to use a code-first approach to accelerate one of the most time-consuming parts of the machine learning lifecycle.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management.
Deep Dive into DataRobot Notebooks
Let’s walk through a step-by-step process with a sample dataset and explore how a data science professional can use DataRobot Notebooks to run an end-to-end experiment by leveraging the DataRobot API and multiple open-source libraries.
We will be writing code in Python, but DataRobot Notebooks also supports R if that’s your preferred language.
Use Case: Predicting Hospital Readmission Probability for a Patient
Augmented Intelligence (AI) in the healthcare industry has been rapidly gaining momentum in recent years. Clinics and hospitals like Phoenix Children’s use AI to predict which patients are at risk of contracting an illness so that they can then prescribe medication and treatment accordingly.
Proactively identifying the likelihood of hospital readmission for a patient goes a long way in ensuring quality care for patients, while decreasing operating costs for hospitals. By predicting which patients are at risk of readmission before they are discharged, doctors can follow appropriate medical procedures to prevent readmission, optimize costs, and enhance the quality of treatment.
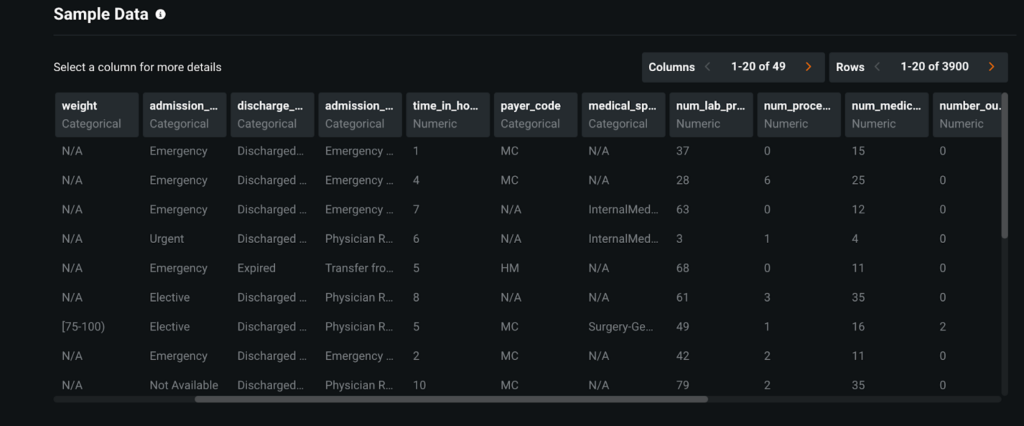
In order to make these predictions, we use indicators like patient diagnosis, length of stay, previous medical records and admissions, age, and other demographics within our dataset.
Create DataRobot Notebooks in a Centralized Notebook Management Space
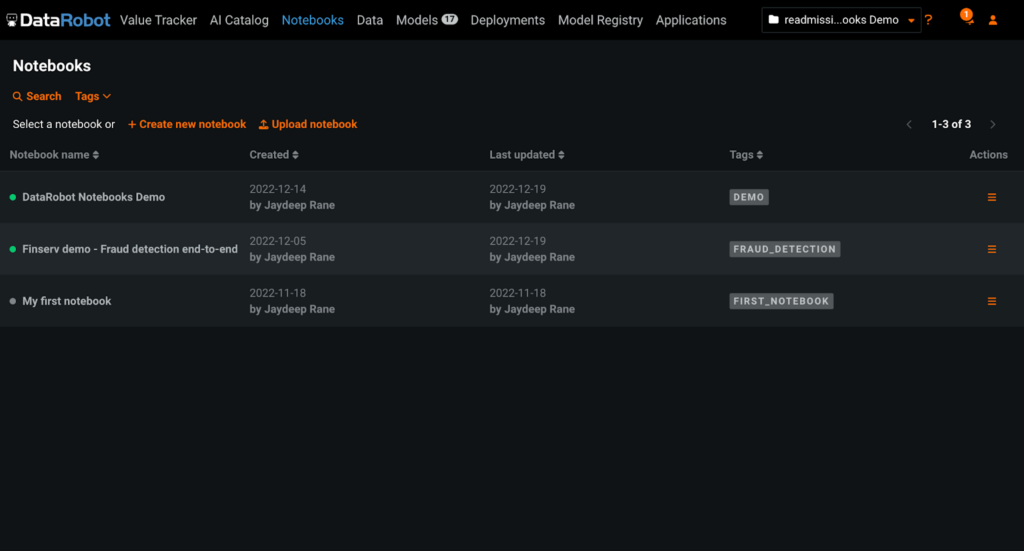
Our first step is to create a notebook. With the DataRobot AI platform, you can either upload your own Jupyter Notebook (.ipynb file) by clicking on the “Upload notebook” button, or create a new notebook by clicking on “Create new notebook.”
This flexibility allows you to import your local code into the DataRobot platform and continue further experimentation using the combination of DataRobot Notebooks with:
- Deep integrations with DataRobot comprehensive APIs
- Auto-scale compute
- A host of open-source libraries
By providing a centralized space to store and access all your notebooks, DataRobot Notebooks enables data science teams to move past siloed local development and collaborate together more productively.
For the purposes of this blog, we will be creating a new notebook from scratch on the DataRobot platform.
Configuring the Notebook Environment, Installing Dependencies and Scaling Compute – All in One Click.
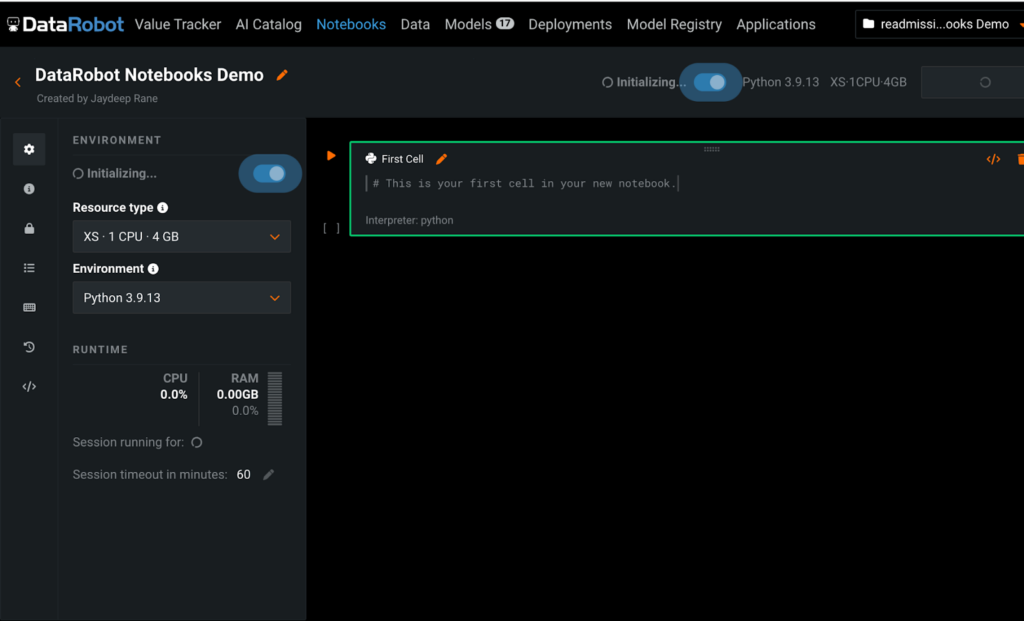
Next, set up the required resource configurations to run AI experiments in the DataRobot Notebook.
Many data scientists aren’t big fans of spending time on the nitty gritty details of setting up infrastructure or low-level configurations. Although this work is necessary to ensure a performant, enterprise-grade development environment, it is a tedious and time-consuming process that data scientists may not have the relevant expertise to complete.
DataRobot Notebooks handles infrastructure configurations with ease by enabling users to spin up a containerized environment for running and executing their notebooks in just a few seconds with a single click. The infrastructure and setup for managing the underlying resources are abstracted from the user and fully managed by DataRobot.
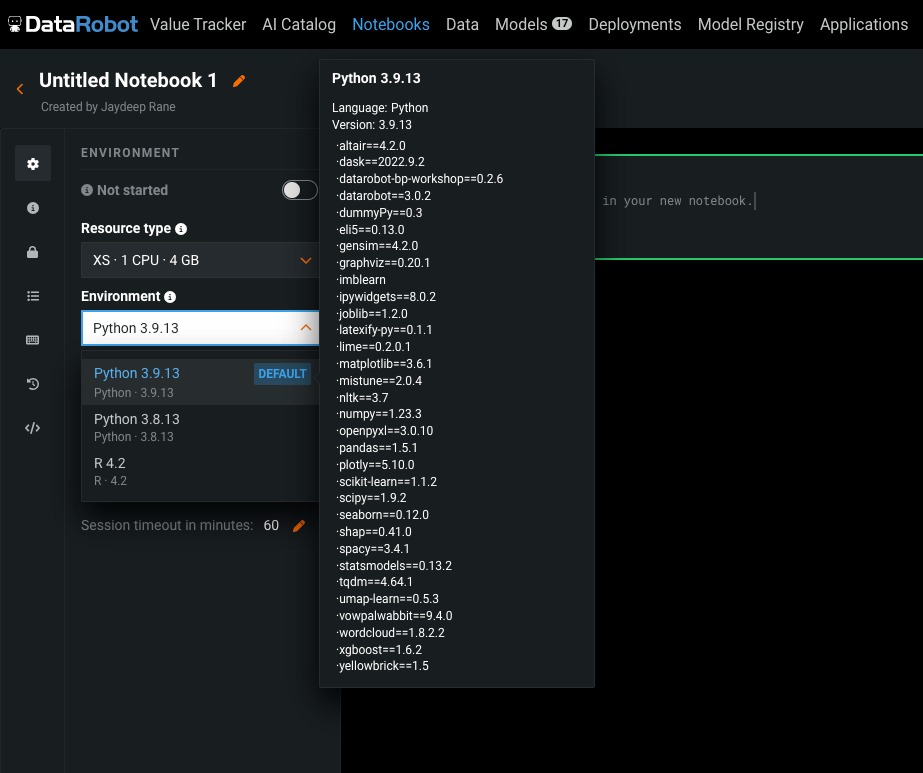
As shown in the images below, these built-in environments come pre-installed with commonly used machine learning libraries, saving time that your data science team would otherwise spend on installation and troubleshooting complex dependencies.
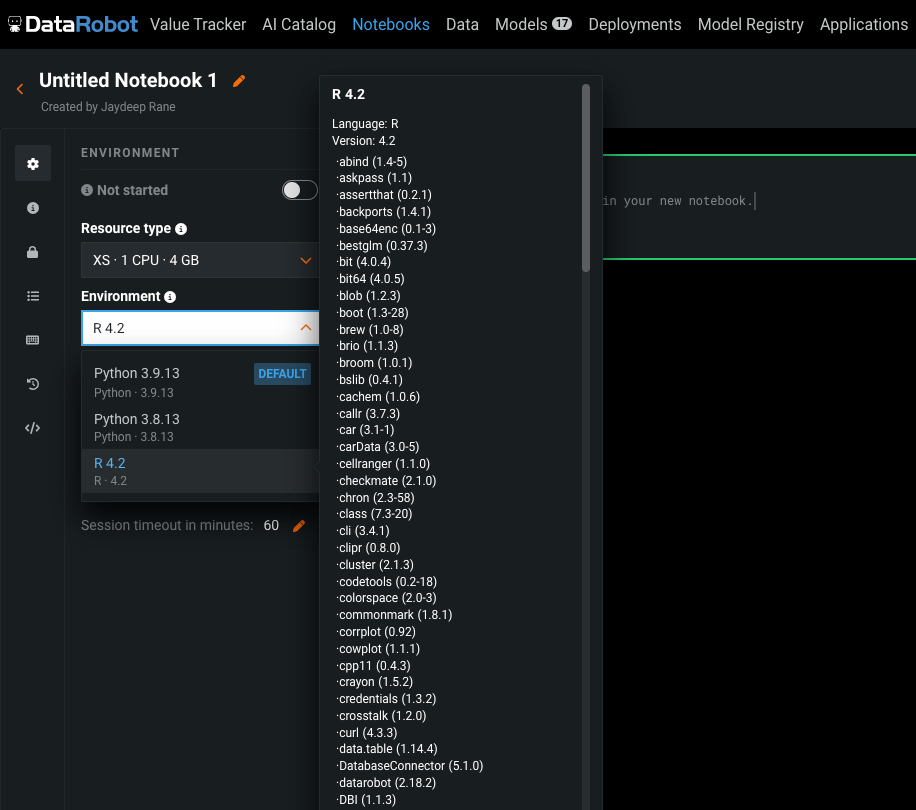
Capabilities Beyond Classic Jupyter for End-to-end Experimentation
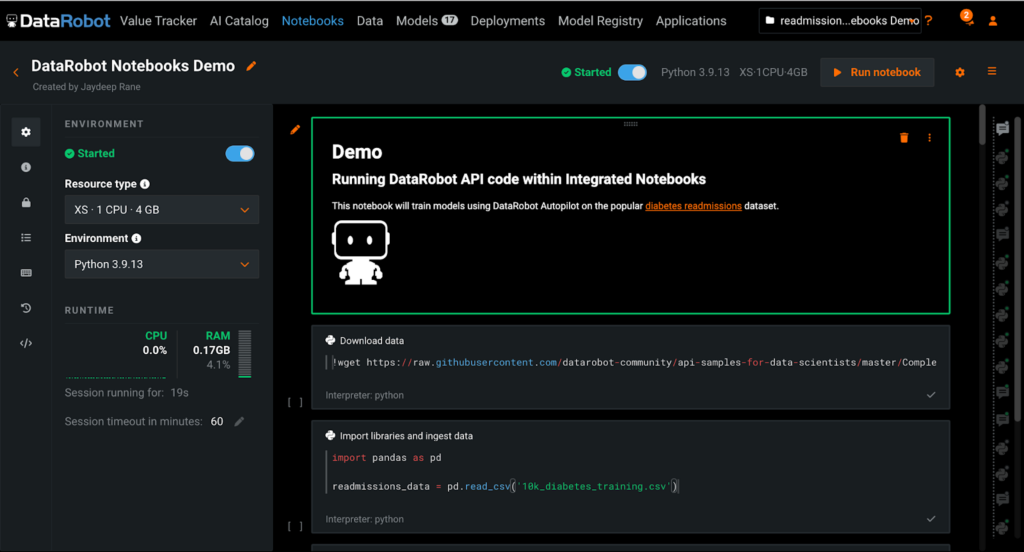
Now that we have set up the notebook environment, let’s explore the capabilities available in DataRobot Notebooks while walking through the process of training and deploying a readmissions prediction model end-to-end.
DataRobot Notebooks are fully compatible with the Jupyter Notebook standard, allowing for interoperability with the rest of the ecosystem. The platform has parity with the core Jupyter capabilities, so users are able to onboard without a steep learning curve. And with enhancements and native integrations beyond the classic Jupyter offerings, DataRobot Notebooks provides a robust and streamlined experience across the ML lifecycle, from data exploration and model development to machine learning operations.
Notebook Environment Variables for Secure Secrets Management
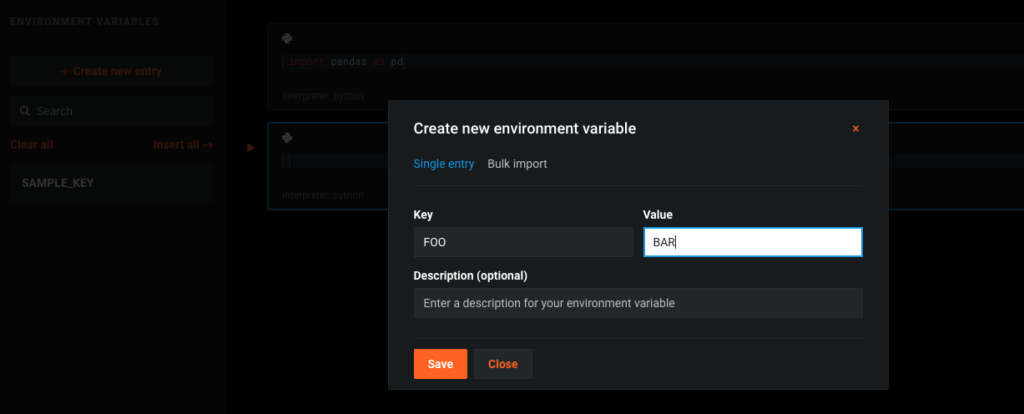
If you have sensitive information you need to reference in your notebooks, such as credentials for connecting to external data sources, you can securely store these secrets via notebook environment variables. These environment variables are stored as encrypted files, and DataRobot handles setting the variables in your environment at the start of each notebook session.
Built-in, Intuitive Cell Functions Promote Better Usability for Exploratory Analysis
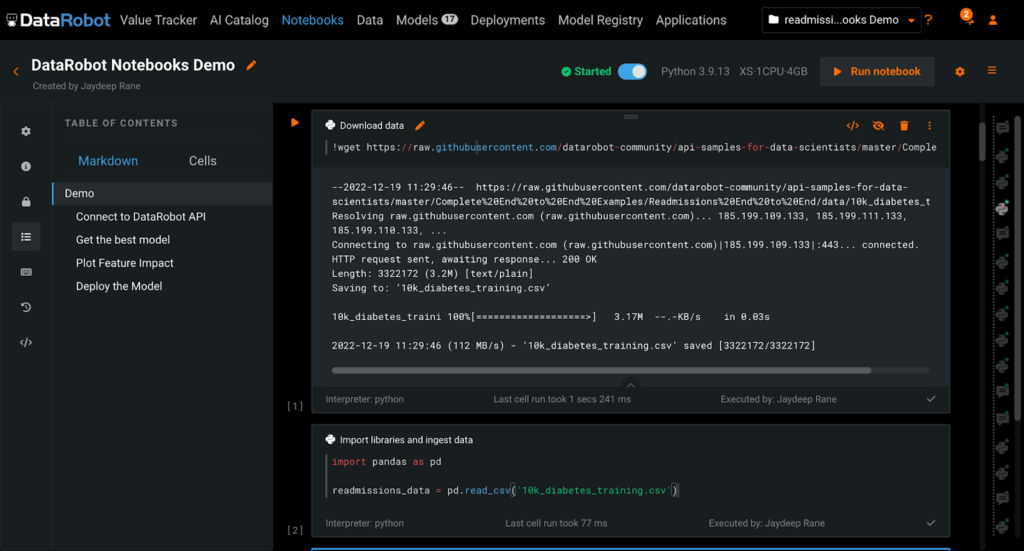
For this experiment, we are going to ingest the hospital readmissions data from a CSV file downloaded to the notebook’s working directory using a shell command. Once converted into a Pandas dataframe, we can perform any exploratory analysis we would like using the Pandas library.
Did you notice?
In the DataRobot left sidebar, there is a table of contents auto-generated from the hierarchy of Markdown cells. With this feature you can more easily navigate the notebook, in addition to presenting your work to teammates and stakeholders. This is similar to the table of contents auto-generated by Google Docs.
Seamless DataRobot API Integration for Hassle-free Workflows
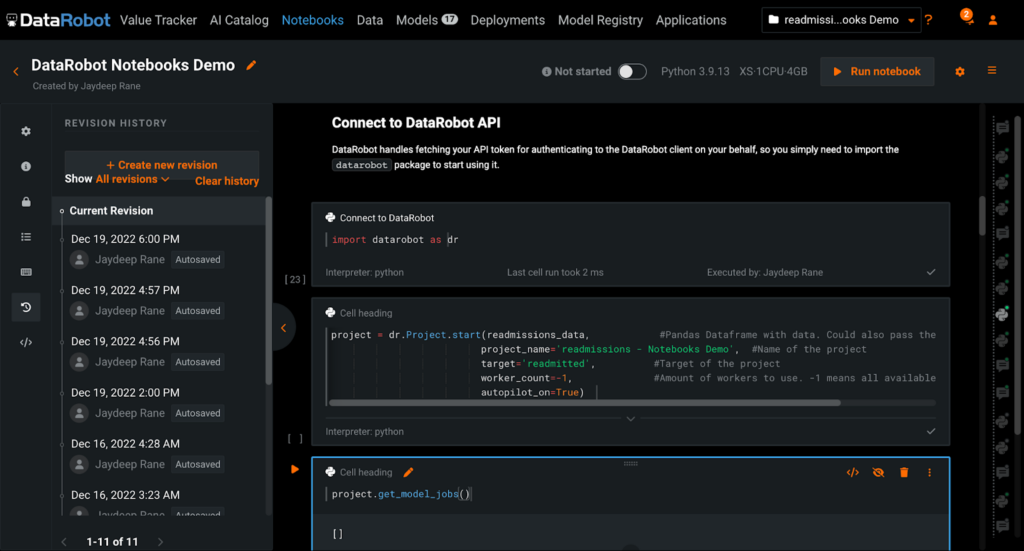
The built-in notebook environments come with the respective DataRobot client (Python or R) preinstalled, and DataRobot handles authenticating the client on the user’s behalf. This means you can skip the extra steps otherwise needed for fetching and configuring the API token to access DataRobot functions. For any packages not in the default images, DataRobot Notebooks provides the flexibility to install those packages during your session. Run the magic command !pip install <your-package> within a code cell. You can also run other shell commands within notebook cells by using the ! notation.
In the image above, we have imported the DataRobot Python client and kickstarted model training using Autopilot, the DataRobot automated machine learning capability. The progress of these modeling tasks can be monitored not just in your notebook, but also within the DataRobot GUI.
Did you notice?
DataRobot has built-in revision history for notebooks, accessible from the sidebar. You can take manual revisions (aka “checkpoints”) of your notebook to version and track the changes to the notebook during development. Automatic revisions are also taken at the end of each notebook session. Each revision of a notebook saves the notebook cells as well as any outputs that were in the notebook at the time of checkpointing. You can preview all of a notebook’s revisions and restore your notebook to a previous version at any point.
Built-in Code Snippets and Interactive Visualizations to Accelerate Experimentation
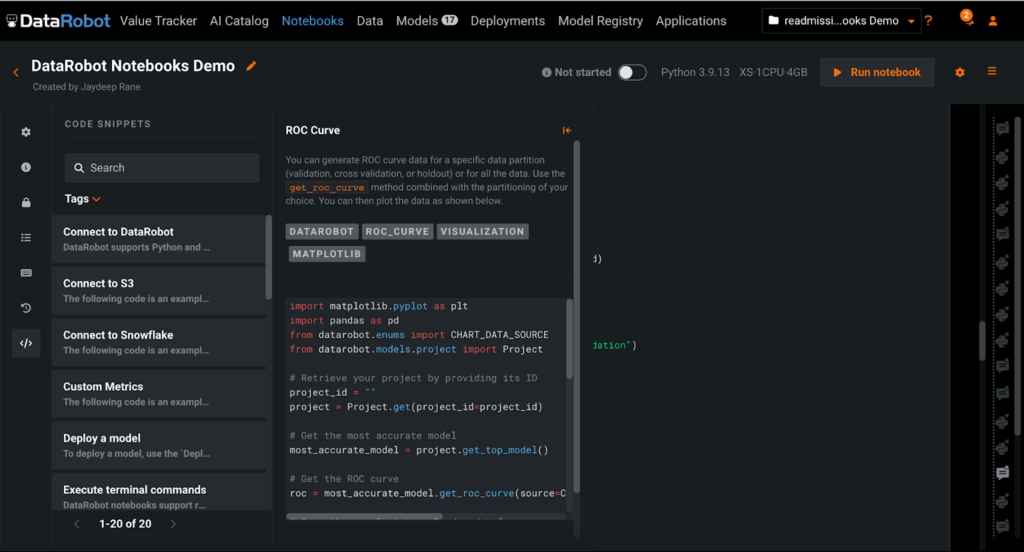
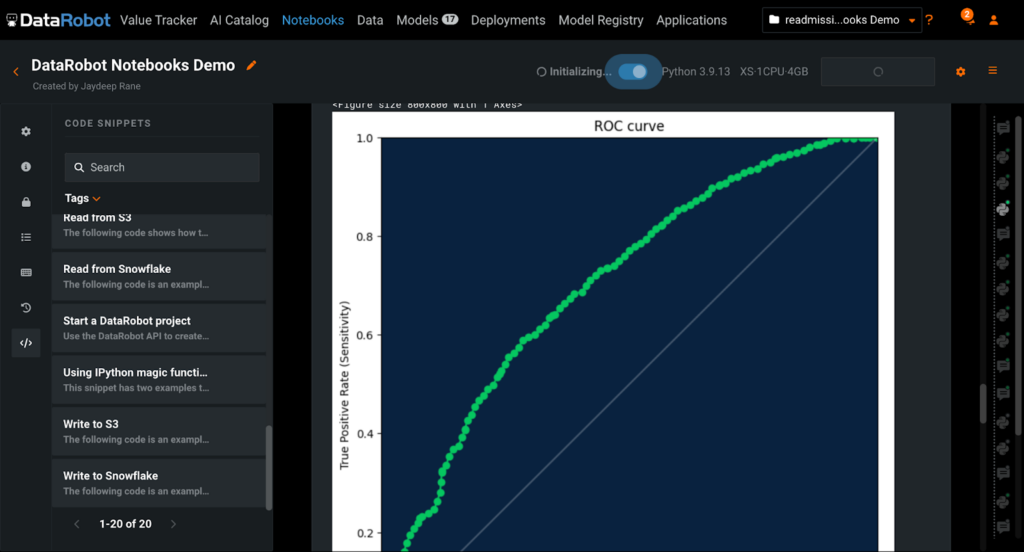
Now that we have explored the dataset and obtained a leaderboard of trained models to choose from, our natural next step is to evaluate these models for accuracy and performance. Since this is a binary classification problem, we can use ROC curves to benchmark the models and then choose the best one.
Code snippets, as seen in the image above, are available for a variety of common data science tasks including connecting to external data sources, deploying models, and generating custom metrics, as well as creating ROC curves. The image below shows the ROC curve plotted for us by the code snippet above and other code snippets available in the sidebar.
In addition, code intelligence capabilities, including autocomplete and inline documentation for each function, are accessible via simple keyboard shortcuts.
These DataRobot features are huge time savers. Instead of spending time looking up boilerplate code or recalling function parameters, you can laser focus on experimentation and expedite code development.
Model Explainability for Responsible and Trusted AI
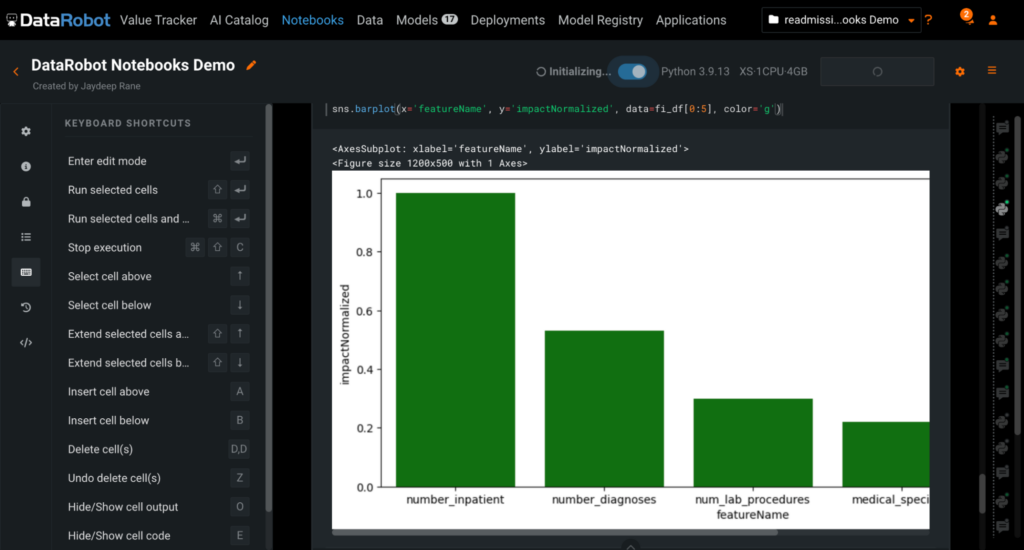
There are no black boxes in DataRobot, meaning that there is an explanation for every prediction, as well as every model. The image above shows a visualization for some of the most important features of the top-performing model on the leaderboard for our hospital readmission dataset. Here we have generated this plot using the Seaborn library, but you can visualize data using any package of your choice.
Did you notice?
In the sidebar, DataRobot Notebooks displays a list of keyboard shortcuts for commonly used cell- and notebook-level actions. The keyboard shortcuts used in DataRobot Notebooks are the same as those in Jupyter, providing users with a familiar user interface and reducing the friction of onboarding to the platform. You can easily reference these keyboard shortcuts while developing and executing your notebook code.
Simulate Real-world Scenarios with Seamless Model Deployment
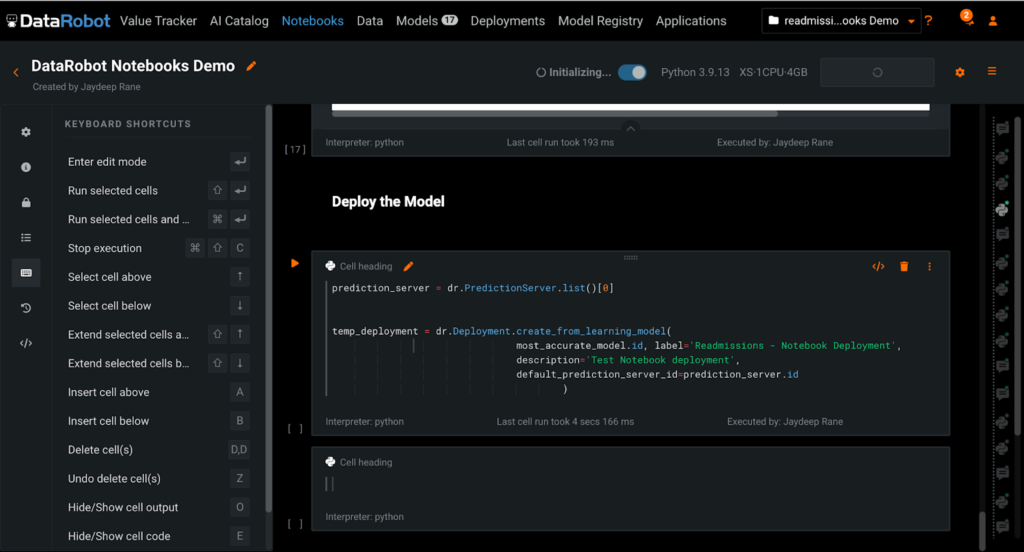
Almost 90% of machine learning models never make it into production. Deploying and operationalizing a machine learning model is a large task for a variety of reasons: differences in coding languages between data scientists and ML engineers, difficulty in setting up the underlying infrastructure for servicing prediction servers, and so on.
Although challenging, model deployment in production is the most crucial stage of the ML lifecycle, ensuring that a data science team’s efforts are driving direct value to the business. Within DataRobot Notebooks, you can deploy a model in just a few lines of code using the DataRobot API. There is also a code snippet you can leverage to save time.
Learn More About DataRobot Notebooks
DataRobot Notebooks address the challenges around collaboration, scalability and security of open-source notebooks, while still providing data science professionals the freedom to work in an environment they’re familiar with. Creative experimentation is possible only when a data scientist devotes more time to research and development and less time to infrastructure and administrative tasks.
With DataRobot Notebooks, high maturity data scientists can elevate their code-first workflows by leveraging DataRobot power tools as well as the ecosystem and open-source community.


