MLFlow + DataRobot API for Tracking Experimentation
As illustrated below, you will use the orchestration notebook to design and run the experiment notebook, with permutations of parameters handled automatically. At the end of the experiments, copies of the experiment notebook will be available, with the outputs for each permutation for collaboration and reference.
Request a DemoExperimentation is a mandatory activity in any machine learning developer’s day-to-day activities. For time series projects, the number of parameters and settings to tune for achieving the best model is in itself a vast search space.
About this Accelerator
Many of the experiments in time series use cases are common and repeatable. Tracking these experiments and logging results is a task that needs streamlining. Manual errors and time limitations may lead to selection of suboptimal models leaving better models lost in global minima.
The integration of DataRobot API, Papermill, and MLFlow automates machine learning experimentation so that is becomes easier, robust, and easy to share.
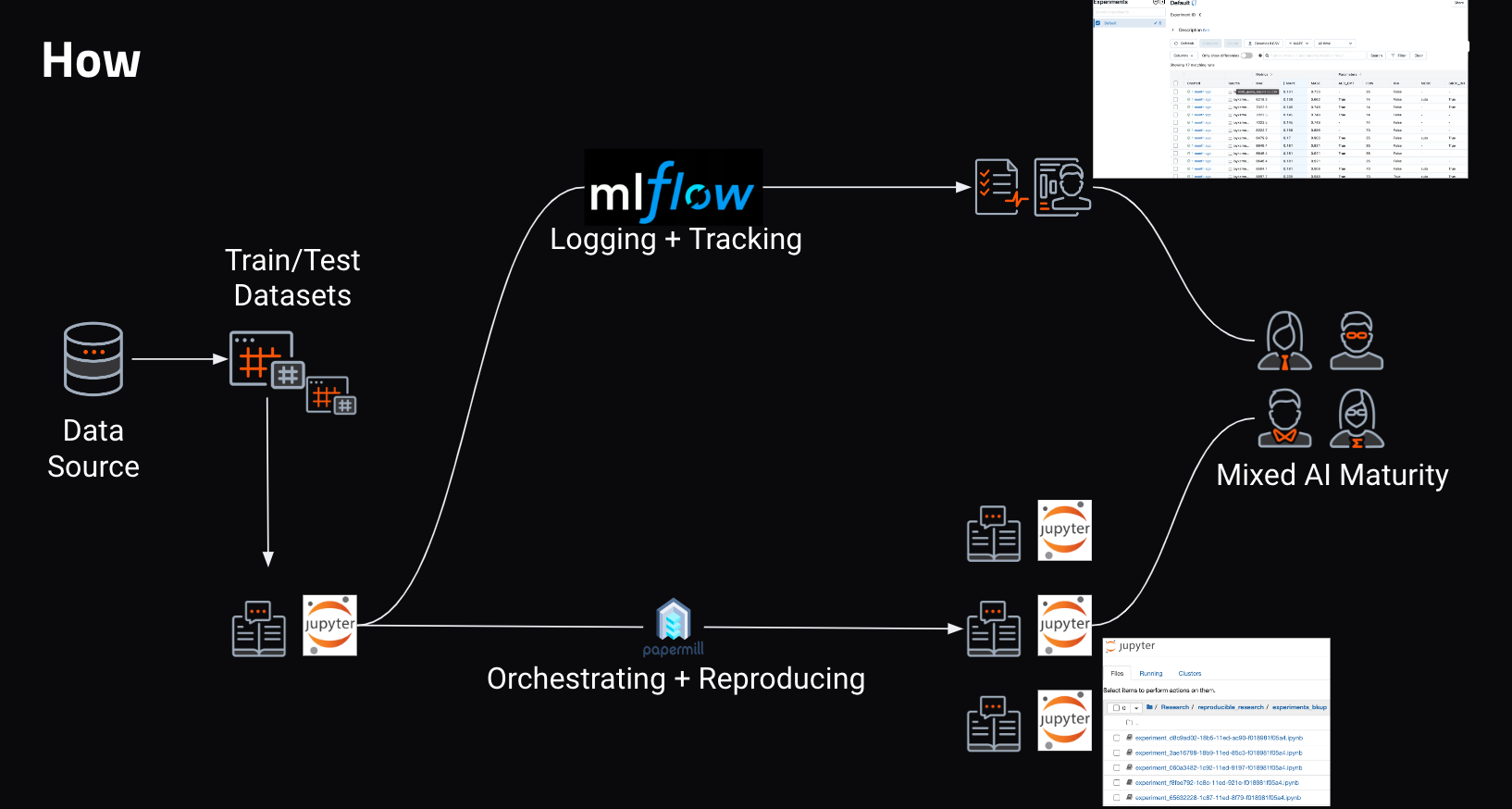
- Use MLFlow with the DataRobot API for Experimentation and Logging (
experiment_notebook.ipynb): This notebook has boilerplate code to use with DataRobot’s Python client to create, start, and get predictions from a DataRobot project. - Integrate MLFlow and Papermill to Track ML Experiments with DataRobot (
orchestration_notebook.ipynb): This notebook provides parameter combinations toexperiment_notebook.ipynbto track the experiments.
Run the mlflow ui command in the same directory to get the dashboard.
1. Use MLFlow with the DataRobot API for Experimentation and Logging
This notebook provides a framework that showcases the integration of MLFlow and Papermill to track machine learning experiments with DataRobot.
This framework outlines how to:
- Use MLFlow with the DataRobot API to track and log ML experiments
- Benefit: Consistent comparison of results across experiments
- Use Papermill with the DataRobot API to create artifacts from machine learning experiments to reduce effort needed for collaboration
- Benefit: Automation of experiments to avoid errors and reduce manual effort
- Execute jupyter notebooks with parameters like Python scripts
- Loop through parameter combinations to run multiple projects; build a Model Factory.
This notebook is the experimentation notebook for running individual time series experiments. Papermill is used to receive parameters from the main notebook (orchestration_notebook.ipynb) and run a copy of this notebook for each combination of the parameters.
The experiment notebook doesn’t require any updates as the parameters are passed from the main notebook. However, this notebook will be updated for different modeling approach like AutoML, Unsupervised learning, etc.
Setup
Bind inputs
In [28]:
FDW = 35
KIA = False
UUID = str("bcf6c090-1899-11ed-a7a1-f018981f05a4")
ACC_OPT = False
SRCH_INT = False
SEGMENTED = False
MODE = "quick"
TRAINING_DATA = "./DR_Demo_Sales_Multiseries_training (1).xlsx"
DATE_COL = "Date"
TRAINING_STOP_DATE = "01-06-2014"
TRAINING_STOP_DATE_FORMAT = "%d-%m-%Y"
DR_AUTH_YAML_FILE = "~/.config/datarobot/drconfig.yaml"
TARGET_COL = "Sales"
KIA_COLS = ["Marketing", "Near_Xmas", "Near_BlackFriday", "Holiday", "DestinationEvent"]
IS_MULTISERIES = True
MULTISERIES_COLS = ["Store"]
REFERENCE_NOTEBOOK = (
"./experiments_bkup/experiment_d666bc12-7602-11ed-99f4-f018981f05a4.ipynb"
)Import libraries
In [8]:
import matplotlib.pyplot as plt
import mlflow
import numpy as np
import pandas as pd
from permetrics.regression import ( # permetrics library for simplifying metric calculation
RegressionMetric,
)Connect to DataRobot
Read more about different options for connecting to DataRobot from the client.
# Authenticate in to your DataRobot instance
import datarobot as dr
import yaml
cred_file = open(DR_AUTH_YAML_FILE, "r")
credentials = yaml.safe_load(cred_file)
DATAROBOT_API_TOKEN = credentials["token"]
DATAROBOT_ENDPOINT = credentials["endpoint"]
client = dr.Client(
token=DATAROBOT_API_TOKEN,
endpoint=DATAROBOT_ENDPOINT,
user_agent_suffix="AIA-AE-MLF-1", # Optional but helps DataRobot improve this workflow
)
dr.client._global_client = client
Out [8]:
Project(Repex_bcf6c090-1899-11ed-a7a1-f018981f05a4)
Import training data
In [3]:
df = pd.DataFrame()
if TRAINING_DATA.find(".csv") != -1:
df = pd.read_csv(TRAINING_DATA, parse_dates=[DATE_COL])
elif TRAINING_DATA.find(".xls") != -1:
df = pd.read_excel(TRAINING_DATA, parse_dates=[DATE_COL])
else:
df = pd.DataFrame()
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7140 entries, 0 to 7139
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Store 7140 non-null object
1 Date 7140 non-null datetime64[ns]
2 Sales 7140 non-null int64
3 Store_Size 7140 non-null int64
4 Num_Employees 7140 non-null int64
5 Returns_Pct 7140 non-null float64
6 Num_Customers 7140 non-null int64
7 Pct_On_Sale 7130 non-null float64
8 Marketing 7140 non-null object
9 Near_Xmas 7140 non-null int64
10 Near_BlackFriday 7140 non-null int64
11 Holiday 7140 non-null object
12 DestinationEvent 7140 non-null object
13 Pct_Promotional 7140 non-null float64
14 Econ_ChangeGDP 80 non-null float64
15 EconJobsChange 1020 non-null float64
16 AnnualizedCPI 240 non-null float64
dtypes: datetime64[ns](1), float64(6), int64(6), object(4)
memory usage: 948.4+ KBPrivate holdout
Set a cutoff date for private holdout. This is necessary to enable the same holdout for all experiments irrespective of feature derivation windows and forecast windows.
In [5]:
training_stop_date = pd.to_datetime(
TRAINING_STOP_DATE, format=TRAINING_STOP_DATE_FORMAT
)In [6]:
df_train = df[df[DATE_COL] < training_stop_date]
df_train.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 7000 entries, 0 to 7125
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Store 7000 non-null object
1 Date 7000 non-null datetime64[ns]
2 Sales 7000 non-null int64
3 Store_Size 7000 non-null int64
4 Num_Employees 7000 non-null int64
5 Returns_Pct 7000 non-null float64
6 Num_Customers 7000 non-null int64
7 Pct_On_Sale 6990 non-null float64
8 Marketing 7000 non-null object
9 Near_Xmas 7000 non-null int64
10 Near_BlackFriday 7000 non-null int64
11 Holiday 7000 non-null object
12 DestinationEvent 7000 non-null object
13 Pct_Promotional 7000 non-null float64
14 Econ_ChangeGDP 80 non-null float64
15 EconJobsChange 1000 non-null float64
16 AnnualizedCPI 230 non-null float64
dtypes: datetime64[ns](1), float64(6), int64(6), object(4)
memory usage: 984.4+ KBModeling
Create a DataRobot project
In [8]:
# Upload data and create a new DataRobot project
project = dr.Project.create(df_train, project_name="Repex_" + UUID)
projectOut [8]:
Project(Repex_bcf6c090-1899-11ed-a7a1-f018981f05a4)
Configure project settings
Set up time series settings for the newly created project.
In [9]:
known_in_advance = KIA_COLS
feature_settings = [
dr.FeatureSettings(feat_name, known_in_advance=True)
for feat_name in known_in_advance
]
time_partition = dr.DatetimePartitioningSpecification(
datetime_partition_column=DATE_COL,
use_time_series=True,
feature_derivation_window_start=-1 * FDW,
feature_derivation_window_end=0,
forecast_window_start=1,
forecast_window_end=14,
)
if KIA:
time_partition.feature_settings = feature_settings
if IS_MULTISERIES:
time_partition.multiseries_id_columns = MULTISERIES_COLS
advanced_options = dr.AdvancedOptions(
accuracy_optimized_mb=ACC_OPT, autopilot_with_feature_discovery=SRCH_INT
)Initiate Autopilot
After creating settings objects, Autopilot is started using the analyze_and_model function.
In [10]:
project.analyze_and_model(
target=TARGET_COL,
partitioning_method=time_partition,
max_wait=3600,
worker_count=-1,
advanced_options=advanced_options,
mode=MODE,
)
print(project.get_uri())
project.wait_for_autopilot()https://app.datarobot.com/projects/63902ec8c32fb2b2077f5da1/models
In progress: 19, queued: 2 (waited: 0s)
In progress: 19, queued: 2 (waited: 1s)
In progress: 19, queued: 2 (waited: 3s)
In progress: 19, queued: 2 (waited: 5s)
In progress: 19, queued: 2 (waited: 7s)
In progress: 19, queued: 2 (waited: 10s)
In progress: 19, queued: 2 (waited: 14s)
In progress: 19, queued: 2 (waited: 21s)
In progress: 19, queued: 2 (waited: 35s)
In progress: 19, queued: 2 (waited: 56s)
In progress: 19, queued: 2 (waited: 78s)
In progress: 19, queued: 0 (waited: 99s)
In progress: 12, queued: 0 (waited: 120s)
In progress: 9, queued: 0 (waited: 141s)
In progress: 6, queued: 0 (waited: 162s)
In progress: 4, queued: 0 (waited: 184s)
In progress: 2, queued: 0 (waited: 205s)
In progress: 1, queued: 0 (waited: 226s)
In progress: 0, queued: 0 (waited: 247s)
In progress: 4, queued: 0 (waited: 268s)
In progress: 4, queued: 0 (waited: 289s)
In progress: 2, queued: 0 (waited: 310s)
In progress: 2, queued: 0 (waited: 331s)
In progress: 0, queued: 0 (waited: 352s)
In progress: 0, queued: 0 (waited: 373s)
In progress: 0, queued: 0 (waited: 395s)
In progress: 1, queued: 0 (waited: 416s)
In progress: 1, queued: 0 (waited: 437s)
In progress: 1, queued: 0 (waited: 458s)
In progress: 1, queued: 0 (waited: 479s)
In progress: 1, queued: 0 (waited: 500s)
In progress: 1, queued: 0 (waited: 521s)
In progress: 1, queued: 0 (waited: 542s)
In progress: 0, queued: 0 (waited: 564s)
In progress: 1, queued: 0 (waited: 585s)
In progress: 1, queued: 0 (waited: 606s)
In progress: 1, queued: 0 (waited: 627s)
In progress: 1, queued: 0 (waited: 648s)
In progress: 1, queued: 0 (waited: 669s)
In progress: 1, queued: 0 (waited: 690s)
In progress: 1, queued: 0 (waited: 711s)
In progress: 1, queued: 0 (waited: 732s)
In progress: 0, queued: 0 (waited: 754s)
In progress: 0, queued: 0 (waited: 775s)
In progress: 0, queued: 0 (waited: 796s)
In progress: 0, queued: 0 (waited: 817s)Get the recommended model
After Autopilot completes, get the recommended model from DataRobot
In [11]:
recommendation = dr.ModelRecommendation.get(project.id)
recommended_model = recommendation.get_model()
print(recommended_model)
DatetimeModel('eXtreme Gradient Boosted Trees Regressor with Early Stopping (learning rate =0.3)')
Performance validation
Create the private holdout from original dataset and get predictions from DataRobot recommended model. Once predictions are available, the predictions are compared to actuals using regression metrics.
In [12]:
dataset = project.upload_dataset(df, forecast_point=training_stop_date)
pred_job = recommended_model.request_predictions(dataset_id=dataset.id)
preds = pred_job.get_result_when_complete()In [14]:
preds["timestamp"] = pd.to_datetime(preds["timestamp"], utc=True)
df[DATE_COL] = pd.to_datetime(df[DATE_COL], utc=True)
preds.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 130 entries, 0 to 129
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 row_id 130 non-null int64
1 prediction 130 non-null float64
2 forecast_distance 130 non-null int64
3 forecast_point 130 non-null object
4 timestamp 130 non-null datetime64[ns, UTC]
5 series_id 130 non-null object
dtypes: datetime64[ns, UTC](1), float64(1), int64(2), object(2)
memory usage: 6.2+ KBIn [15]:
if IS_MULTISERIES:
df_comparison = df[MULTISERIES_COLS + [DATE_COL, TARGET_COL]].merge(
preds[["prediction", "timestamp", "series_id"]],
left_on=MULTISERIES_COLS + [DATE_COL],
right_on=["series_id", "timestamp"],
)
else:
df_comparison = df[[DATE_COL, TARGET_COL]].merge(
preds[["prediction", "timestamp"]], left_on=[DATE_COL], right_on=["timestamp"]
)
assert df_comparison.shape[0] == preds.shape[0]
df_comparison.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 130 entries, 0 to 129
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Store 130 non-null object
1 Date 130 non-null datetime64[ns, UTC]
2 Sales 130 non-null int64
3 prediction 130 non-null float64
4 timestamp 130 non-null datetime64[ns, UTC]
5 series_id 130 non-null object
dtypes: datetime64[ns, UTC](2), float64(1), int64(1), object(2)
memory usage: 7.1+ KB
Plotting actuals vs predicted for visual verificationIn [24]:
if not IS_MULTISERIES:
plt.plot(
df_comparison["timestamp"],
df_comparison["prediction"],
label="Prediction",
color="red",
)
plt.plot(
df_comparison["timestamp"],
df_comparison["Sales"],
label="Actuals",
color="blue",
alpha=0.5,
)
else:
df_viz = df_comparison[
df_comparison["series_id"] == df_comparison.series_id.unique()[0]
]
plt.plot(df_viz["timestamp"], df_viz["prediction"], label="Prediction", color="red")
plt.plot(
df_viz["timestamp"], df_viz["Sales"], label="Actuals", color="blue", alpha=0.5
)
plt.xticks(rotation=90)
Out [24]:
(array([16224., 16226., 16228., 16230., 16232., 16234.]),
[Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, '')])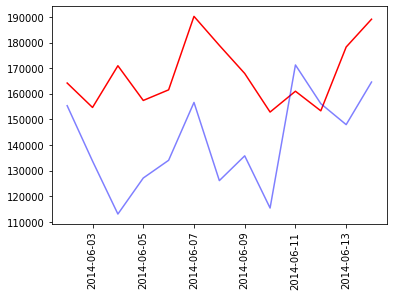
In [17]:
# Validate experiment performance
evaluator = RegressionMetric(
df_comparison[TARGET_COL].values, df_comparison["prediction"].values
)Tracking and logging experiments
Log experiment metrics and parameters for display and comparison on the MLFlow UI.
In [30]:
with mlflow.start_run():
mlflow.log_param("Project URL", project.get_uri()) # URL for DataRobot Project
mlflow.log_param(
"Notebook Location", REFERENCE_NOTEBOOK
) # location of final notebook for reference
mlflow.log_param("Feature Derivation Window", FDW) # feature derivation used
mlflow.log_param(
"Enabled Known In Advance features", KIA
) # known in advance setting
mlflow.log_param(
"Ran Accuracy Optimized BPs", ACC_OPT
) # accuracy optimized setting
mlflow.log_param(
"Enabled Search Interactions option", SRCH_INT
) # search for interactions setting
mlflow.log_param("Autopilot Mode", MODE) # autopilot mode
mlflow.log_artifact(REFERENCE_NOTEBOOK) # location of final notebook for reference
# logging model performance metrics
mlflow.log_metric("MASE", evaluator.MASE())
mlflow.log_metric("MAPE", evaluator.MAPE())
mlflow.log_metric("RMSE", evaluator.RMSE())
mlflow.log_metric("MAE", evaluator.MAE())
mlflow.log_metric("R2", evaluator.R2())
mlflow.log_metric("Support", preds.shape[0])2. Integrate MLFlow and Papermill to Track ML Experiments with DataRobot
This notebook outlines how to:
- Use MLFlow with DataRobot API to track and log machine learning experiments
- Benefit: Consistent comparison of results across experiments
- Use Papermill with DataRobot API to create artifacts from machine learning experiments to reduce effort needed for collaboration
- Benefit: Automation of experiments to avoid errors and reduce manual effort.
- Execute Jupyter notebooks with parameters like Python scripts
- Loop through parameter combinations to run multiple projects; build a Model Factory.
This orchestration notebook illustrates the framework to integrate MLFlow and Papermill with the DataRobot API to run the experiment notebook with different parameters per experiment.
This notebook will run the experiment_notebook.ipynb with different parameters
Required Python Libraries:
Setup
Import libraries
uuid is used to generate unique identifiers for our experimentation. itertools is used to generate permutations of all experiments.
In [1]:
import itertools
import os
import uuid
import papermill as pmUse the snippet below to create requisite folders.
In [2]:
if not os.path.isdir("./experiments_bkup"):
os.mkdir("./experiments_bkup")Configure use case settings
These are the basic settings needed to run Time Series projects through the DataRobot API. These settings have to be updated for the intended use case.
In [3]:
DR_AUTH_YAML_FILE = (
"~/.config/datarobot/drconfig.yaml" # yaml file with authentication details
)
TRAINING_DATA = (
"./DR_Demo_Sales_Multiseries_training (1).xlsx" # location of training dataset
)
DATE_COL = "Date" # datetime column
TRAINING_STOP_DATE = "01-06-2014" # cutoff date for private holdout for experiments
TRAINING_STOP_DATE_FORMAT = (
"%d-%m-%Y" # datetime format specifier for TRAINING_STOP_DATE
)
TARGET_COL = "Sales" # target column for the usecase
KIA_COLS = [
"Marketing",
"Near_Xmas",
"Near_BlackFriday",
"Holiday",
"DestinationEvent",
] # known in advance features
IS_MULTISERIES = True # does the dataset have multiple time series
MULTISERIES_COLS = [
"Store"
] # if the dataset has multiple ts, columns that uniquely identify a ts.Scenario
There are many experiments that need to be tried in Time Series projects. The most basic ones include experimenting with multiple forecast derivation windows and enabling known in advance features. Only these two parameters can result in atleast six different experiments as shown by the example in the cell below;
First experiment series set
This example starts with basic set of experiments to identify quickly if the dataset has any signal. You will use a combination of feature derivation windows and known in advance features to do so.
In [4]:
fdws = [
35,
70,
14,
] # The Time Series feature derivation window parameter values to experiment
kias = [False, True] # The known in advance parameter values to experiment withRun multiple projects for all permutations of the values from the above two parameter sets. This can be seen as a “DataRobot Project Factory” where you will run multiple projects using Papermill. Papermill allows us to send parameters to a Jupyter notebook and execute if for those parameters. It will also create copies of the notebook execute in a specified folder.
In [5]:
INPUT_PATH = "./experiment_notebook.ipynb"
for item in itertools.product(fdws, kias):
UUID = str(uuid.uuid1())
OUTPUT_PATH = "./experiments_bkup/experiment_{}.ipynb".format(UUID)
pm.execute_notebook(
input_path=INPUT_PATH,
output_path=OUTPUT_PATH,
parameters={
"FDW": item[0],
"KIA": item[1],
"UUID": UUID,
"DR_AUTH_YAML_FILE": DR_AUTH_YAML_FILE,
"TRAINING_DATA": TRAINING_DATA,
"DATE_COL": DATE_COL,
"TRAINING_STOP_DATE": TRAINING_STOP_DATE,
"TRAINING_STOP_DATE_FORMAT": TRAINING_STOP_DATE_FORMAT,
"TARGET_COL": TARGET_COL,
"KIA_COLS": KIA_COLS,
"IS_MULTISERIES": IS_MULTISERIES,
"MULTISERIES_COLS": MULTISERIES_COLS,
"REFERENCE_NOTEBOOK": OUTPUT_PATH,
},
)Executing: 0%| | 0/25 [00:00<?, ?cell/s]
Executing: 0%| | 0/25 [00:00<?, ?cell/s]
Executing: 0%| | 0/25 [00:00<?, ?cell/s]
Executing: 0%| | 0/25 [00:00<?, ?cell/s]
Executing: 0%| | 0/25 [00:00<?, ?cell/s]
Executing: 0%| | 0/25 [00:00<?, ?cell/s]Experiment results
After completion of the above set of experiments, MLFlow dashboard can be invoked for perusal of the results. Run the below cell or the contents of the cell in command line to run the MLFlow server and UI.
In [6]:
# Ensure to stop the execution of this cell before running next cells
!mlflow ui[2022-12-07 15:47:24 +0530] [20341] [INFO] Starting gunicorn 20.1.0
[2022-12-07 15:47:24 +0530] [20341] [INFO] Listening at: http://127.0.0.1:5000 (20341)
[2022-12-07 15:47:24 +0530] [20341] [INFO] Using worker: sync
[2022-12-07 15:47:24 +0530] [20345] [INFO] Booting worker with pid: 20345
^C
[2022-12-07 15:58:55 +0530] [20341] [INFO] Handling signal: int
[2022-12-07 15:58:55 +0530] [20345] [INFO] Worker exiting (pid: 20345)
Further experimentations
Once comfortable with the initial set of experiments and results, you can further expand the experiment combinations as below. The advantage of parameterization of the notebook is that you can run only the experiments that are needed and you can keep building on the experiments you already ran.
For example, you can run accuracy optimized blueprints set as “is false” by default if you have run that experiment in the prior cells. Time and Compute can be saved by only using the True option for the parameter in subsequent experiments.
In [7]:
# Import datarobot library for the enums
import datarobot as drIn [8]:
fdws = [35, 14] # TS feature derivation window parameter values to experiment
kias = [False] # Known in advance parameter values to experiment
acc_opt = [True] # Enable accuracy optimized blueprints
search_int = [True] # Search for interactions between features
mode = [dr.enums.AUTOPILOT_MODE.FULL_AUTO] # Autopilot mode values to experimentIn [9]:
INPUT_PATH = "./experiment_notebook.ipynb"
for item in itertools.product(*[fdws, kias, acc_opt, search_int, mode]):
UUID = str(uuid.uuid1())
OUTPUT_PATH = "./experiments_bkup/experiment_{}.ipynb".format(UUID)
pm.execute_notebook(
input_path=INPUT_PATH,
output_path=OUTPUT_PATH,
parameters={
"FDW": item[0],
"KIA": item[1],
"ACC_OPT": item[2],
"UUID": UUID,
"DR_AUTH_YAML_FILE": DR_AUTH_YAML_FILE,
"TRAINING_DATA": TRAINING_DATA,
"DATE_COL": DATE_COL,
"TRAINING_STOP_DATE": TRAINING_STOP_DATE,
"TRAINING_STOP_DATE_FORMAT": TRAINING_STOP_DATE_FORMAT,
"TARGET_COL": TARGET_COL,
"KIA_COLS": KIA_COLS,
"IS_MULTISERIES": IS_MULTISERIES,
"MULTISERIES_COLS": MULTISERIES_COLS,
"REFERENCE_NOTEBOOK": OUTPUT_PATH,
},
)Executing: 0%| | 0/25 [00:00<?, ?cell/s]
Executing: 0%| | 0/25 [00:00<?, ?cell/s]
In [12]:
!mlflow ui
[2022-12-07 17:04:35 +0530] [45452] [INFO] Starting gunicorn 20.1.0
[2022-12-07 17:04:35 +0530] [45452] [INFO] Listening at: http://127.0.0.1:5000 (45452)
[2022-12-07 17:04:35 +0530] [45452] [INFO] Using worker: sync
[2022-12-07 17:04:35 +0530] [45457] [INFO] Booting worker with pid: 45457
^C
[2022-12-07 17:05:36 +0530] [45452] [INFO] Handling signal: int
[2022-12-07 17:05:36 +0530] [45457] [INFO] Worker exiting (pid: 45457)
Explore more AI Accelerators
-
Object Classification on Video with DataRobot Visual AI
This AI Accelerator demonstrates how deep learning model trained and deployed with DataRobot platform can be used for object detection on the video stream (detection if person in front of camera wears glasses).
Learn More -
Prediction Intervals via Conformal Inference
This AI Accelerator demonstrates various ways for generating prediction intervals for any DataRobot model. The methods presented here are rooted in the area of conformal inference (also known as conformal prediction).
Learn More -
Reinforcement Learning in DataRobot
In this notebook, we implement a very simple model based on the Q-learning algorithm. This notebook is intended to show a basic form of RL that doesn't require a deep understanding of neural networks or advanced mathematics and how one might deploy such a model in DataRobot.
Learn More -
Dimensionality Reduction in DataRobot Using t-SNE
t-SNE (t-Distributed Stochastic Neighbor Embedding) is a powerful technique for dimensionality reduction that can effectively visualize high-dimensional data in a lower-dimensional space.
Learn More